6. Memory Hierarchy
Basics¶

如上图,对于多周期 CPU,往往取 mem 的时候用多周期去取,而且会有一个 ready bit。
Cache¶

如上图,可以参考我在 csapp 中的笔记。
Example: the intrinsity FastMATH Processor¶

如上图,这个 cache 的参数是:
- block size: 16 words = 64 bytes = \(2^6\) bytes
- corresponding memory: 16 KB = \(2^{14}\) bytes
从而,我们的
- block offset bits: 6
- index bits: 14 - 6 = 8
- tag bits: 32 - 10 - 6 = 16
具体的实现中,可以看到:
- mux 的输出式 32 位的,且忽略地址的前两位(也就是默认地址必须是 4 的倍数,也就是取的值是 4 bytes = 1 word 的)
- 说明这个 cache 是 word-addressable 的
- Hit bit 跟两个有关:cache.valid_bit ?= 1,以及 cache.tag ?= input.tag。
Test: SPEC2000¶
使用 SPEC2000 benchmark 进行测试,结果如下:
| Instruction miss rate | Data miss rate | Effective combined miss rate |
|---|---|---|
| 0.4% | 11.4% | 3.2% |
由于 instruction 一般而言是顺序执行的,因此 locality 一般比较好。
而 data 一般而言总是难以避免随机读取,而且可能就只读一个值,因此 data miss rate 一般而言比较差。
Split Cache and Combined Cache¶
我们的流水线用的是 split cache,为的就是避免结构竞争。
Cache Performance Analysis¶

如上图,如果要将 4 个 block 从内存传到 cache,那么就需要:
- 1 cycle 将地址传给 memory
- 15 cycles 等待取内存数据
- 1 (bus) cycle 数据从总线上传回 CPU
由于数据从总线上传回 CPU 这一步的同时可以传第下一个 address,因此总共耗时:\((1 + 15) * 3 + (1 + 15 + 1) = 65\)。
由于内存数据需要先写到 cache 里,然后再花费一个周期从 cache 读入寄存器,因此,一共需要 66 个 clock cycles。
Observation¶
从而,在 miss rate = 10% 的情况下,使用 cache 和不用 cache 的性能是有显著差距的。
但是,我们也明显看到:使用 cache 需要 7.5 clks,其中 6.6 的 clk cycle 就是白白等待 cache。
这说明,我们的 cache 有待改进:reduce miss rate。
同时,我们也可以看到,如果我们将 block size 上调至 16 words(同时假设 miss rate 不变),使用 cache 甚至比不用 cache 更加耗时。这一切的原因,就是无法并行读取 memory。
这说明,我们的 memory 也需要跟 cache 配套:reduce miss penalty。
Reduce Miss Penalty¶

如图,传统的 memory 就是第一种——每次只能传一个 byte。
一个显然的想法是,我们可以增加带宽,从而一次可以传多个 bytes。
- 这种方式是不常用的,一个原因是如果需要加宽总线的话,代价太高
因此,我们就想:传输并不是瓶颈,获取地址才是。因此,与其总线加宽(并行传输+并行读取),不如就仅仅并行读取。具体方法如下:
我们将一个 word 的 4 个不同的 bytes 放在 4 个不同的 memory banks 里,然后 memory bank 取数据是并行/分时启动的,但是传输数据是串行的。
- 由于取数据是瓶颈,因此这种方式也很好
- 这种方式是现在的主流
Wide Memory¶

如图:如果传输的线宽为 2 words (8 bytes),那么我们就可以只需要传输两次,而不是 16 次。
图示如下:

Interleaved Memory¶

如图:如果线宽就是 1 个 word,但是分为 4 个 banks,然后 bank 的之间的启动时间间隔为 1 cycle(从而取出数据的时间也是 1 cycle)
图示如下:

如果采用的这样的 memory,那么平均访问时间就是 90% * 1 + 10% * (1 + 1 + 15 + 4 * 1) = 3 cycles。
如果 block size 是 16 words,那么也是 90% * 1 + 10% * (1 + 1 + 15 + 16 * 1) = 4.2 cycles。相比 4 block 的情况,没有太大的问题。
Reduce Miss Rate¶
可以采用 multi-way 的方式来 reduce cache miss。
Cache Metric¶

忽略软件上的影响,我们只看硬件。
如果使用了 2-way,那么
- miss rate 显然可以减少
- 同时由于 2-way 的逻辑门增加了,因此时钟周期可能会更长一点
权衡利弊之后,如果只看 Average Memory Access Time 这个 metric,那么 2-way 总体上还是比 1-way 要略好一些。
但是,CPU 不仅有 memory access,还有每一条指令的执行。如果 clock cycle 减慢了,那么受影响的还有指令的执行。因此,加上这一点之后,1-way 还是比 2-way 更好一些。
因此,我们一般用 CPU time 来作为 cache metric。CPU time 的计算方法如下:

比如说,上面的 CPU TIME 1-way:
- 2 * 1.0: CPU execution clock cycles per instruction
- 1.5: 100% (imem access per instruction) + 50% (dmem access per instruction)
- 1.5 * 0.014 * 75: Memory-stall clock cycles per instruction
另外,假如 block is dirty,那么我们还需要 write back to memory,这又是一次开销。在具体计算的时候,我们还需要加上。
Factors of Cache Metric¶
Cache metric 有几个 factors:
- CPI: 比如使用多发射、超标量啥的技术,就可以将 CPI 降到 1,甚至比 1 还小
- Clock Cycle Time: 现代处理器的主频不断提升,因此 clock cycle 一直在减小
但是,由于 memory 技术没怎么进步,因此,
- 如果 CPI 下降了,Memory-stall clock cycle 并没有下降
- 如果 Clock Cycle Time,由于内存访问时间不变,因此 Memory-stall clock cycles 反而会提升,从而更加拖后腿
- 有可能 clock cycle time 降了一半,但是 CPU time 只是降到了原来的 0.81 倍,性能只提升到原来的 1.23 倍
Space Overhead of Cache¶
假设我们的 cache 是 1-way associative cache in 32-bit addressable space with
- block size: 4 words = 16 bytes = \(2^4\) bytes
- corresponding memory: 4 KB = \(2^{14}\) bytes
从而,我们的
- block offset bits: 4
- index bits: 14 - 4 = 10
- tag bits: 32 - 10 - 4 = 18
从而,cache 实际上需要占用的空间大小是: $$ 2 ^ {10} * (16 + 18 / 8 + 1 / 8) \mathrm{~bytes} = 18.375 \mathrm{~KB} $$ 其中,
- 16 是 block size
- 18 和 1 分别是 tag bits and valid bit (i.e. 上图的 "V")
- 后面除以 8 是为了将 bit 转换为 byte
Associativity of Cache¶
如果是 fully associative,使用硬件实现,一般就用三态门。但是硬件实现代价太高,而且会导致 clock cycle 大大减慢,因此一般不会这样做。
从而,我们一般用的是 set-associative。具体使用多少 set,还是需要权衡利弊。因为,对于总量相同的,如果采用更多的 set
- 用于选择”具体取哪一个 set“的逻辑门电路增加,从而会导致 clock cycle 时间增加
- 同样的内存容量,set 数量越多,统计上来看,冲突的概率就越小,因此 miss rate 会降低
Example¶
如果一个 cache 是:
- 4K block size
- each block contains 4 words
- a word equals to 4 bytes
- with byte-adressable memory and 32-bit address space
那么,自然,offset 就是 4 bits。但是,根据 associativity 的不同,index 和 tag 也会有所不同:
| direct-mapped | 2-way associative | 4-way associative | full associative | |
|---|---|---|---|---|
| index bits | 12 | 11 | 10 | 0 |
| tag bits | 16 | 17 | 18 | 28 |
另外,对于比较小的 associativity,大概就是这样实现的:

- 对于上图中每一列,都检测是否 valid 且相等
- 然后根据检测的结果,来输出 hit 以及 data
- 输出 data 的时候,我们当然知道(正常情况下)4 个与门至多只有一个为真,因此是可以直接用三态门的。
- 在这里,与其使用 mux,不如直接每一列的 32 bit 的 data 线,都和该列的与门并上,然后再放入一个 fan-in=4 的或门就完了。
Write Strategies of Cache¶
可以参考 csapp notes。这里的四种策略,其实要分为两组,每组两个。每一组分别对应 hit 和 miss 两种情况:
Cache 中已经有数据: Hit
- Write through: 同时写到 cache 以及 memory
- Write back: 只写到 cache,且 mark it as dirty;直到被替换了,才写进内存
Cache 中还没有数据: Miss
- Write allocate: 分配一个 block(有必要可以替换),将 memory data fetch 进这个 block,然后再修改其中的对应的数据,并 mark as dirty
- 既然数据已被修改,为何还需要 fetch original data into block?因为我们只修改 block 中的一小部分,并不是整个 block。未修改的部分,就是 original data
- Non-Write allocate: 直接写进内存
不难发现:Write through 和 non-allocate 都是每一次都直接写入内存;而 write back 和 write allocate 就是能不写则不写。因此,"write through + non-allocate" 和 "write back + write allocate" 是相配的。
Inclusive, Exclusive and NI/NE Caching
这里假设只有 L1, L2 and memory.
Inclusive Cache(包容性缓存)¶
包容性缓存的主要特点是:L1 缓存中的数据地址也必须在 L2 缓存中存在(即 \(L_1 \subset L_2\)),但是不要求数据内容一样。
- 兼容性:
- Write Through: 包容性缓存适合 Write Through 策略,因为每次写操作都会直接写入主存储器,这与缓存层级之间的包容性保持一致。
- Write Back: 包容性缓存与 Write Back 策略兼容,因为数据可以在 L1 中进行多次修改,最终会写回 L2 和主存储器。
- Write Allocate: 包容性缓存支持 Write Allocate,因为新数据会分配到 L1 和 L2 缓存中。
- Non-Write Allocate: 包容性缓存同样支持 Non-Write Allocate 策略,因为不需要将数据块加载到缓存中就可以直接写入主存储器。
- Read and Flush:
- Read 的时候,应该 L1 和 L2 均有一个备份
- Flush 的时候,如果 L2 被 flush,那么 L1 的对应地址也应该被 invalidate
Exclusive Cache(独占性缓存)¶
独占性缓存的主要特点是:L1 缓存中的数据不在 L2 缓存中存在(即 \(L_1 \cap L_2 = \emptyset\))。L1 和 L2 缓存共同利用缓存空间,不会存储重复的数据块。
- 兼容性:
- Write Through: 独占性缓存很不适合 Write Through 策略。原因很简单:write through 就是需要同时写 L1 和 L2 的,但是 exclusive 又要求同一个地址不能在这两块中同时出现。
- i.e. L1 write hit 是,要同时写入 L1 和 L2,但是此处 L2 对应的地址,由 exclusive 可知,根本就不存在
- Write Back: 独占性缓存与 Write Back 策略非常兼容,L1 中的数据在需要时才会写入 L2,充分利用缓存空间。
- i.e. L1 write hit 是,只写入 L1,从而不会造成重复数据
- Write Allocate: 独占性缓存支持 Write Allocate,因为新数据会分配到 L1 缓存中,腾出 L2 缓存空间给其他数据。
- i.e. L1 write miss 时,会删除 L2 中的对应数据(如果存在),然后将该数据加载到 L1 中
- Non-Write Allocate: 独占性缓存支持 Non-Write Allocate,因为它能够直接在主存储器中写入数据,而不需要占用缓存空间。
- i.e. L1 write miss 时,直接写到 L2 去。不会造成重复数据。
- Write Through: 独占性缓存很不适合 Write Through 策略。原因很简单:write through 就是需要同时写 L1 和 L2 的,但是 exclusive 又要求同一个地址不能在这两块中同时出现。
- Read and Flush:
- Read 的时候,数据应该直接写到 L1 中,不应该经 L2 的手
- Flush 的时候,如果 L1 被 flush,那么把 L1 的数据存到 L2
- 这不是强制要求。只是这样做,能够在保证 exclusive 的同时,访问速度也有保证
NI/NE Cache(非包容性/非排他性缓存)¶
非包容性/非排他性缓存是一种灵活的缓存策略:L1 和 L2 缓存中的数据既可以重叠也可以独立存在。这种缓存策略不强制要求包容性或排他性。
- 兼容性:肯定都是兼容的
- Read and Flush: 策略可以非常随意
Replacement Strategies of Cache¶
一般而言,有 LRU (Least Recently Used) 和 FIFO 两种策略。
LRU¶
在 associativity 比较多的时候,LRU 的实现开销很大;而且 LRU 本身也不比随机算法好多少 (in practice)。
从而,我们一般采用树形结构近似:

如上图:我们每一次访问一个节点的时候,就沿着树的路径,将所有树上的设成对应的值(0 代表左侧 more recently used,1 代表右侧 more recently used)。
比如说:如果访问了第 5 个块的时候,就会将
- "2" 设为 1
- "5" 设为 0
- "6" 设为 1
然后,需要替换的时候,我们就沿着树,从树的根节点往下走:如果某个节点为 0,那就说明左侧 more recently used,因此就往右走;如果某个节点为 1,那就说明左侧 more recently used,因此就往左走。
FIFO¶
FIFO 就更简单了。给每一个 block 设置一个 "I'm the first" 的 bit 即可。
如果有 valid bit 为 0 的,那就直接写入,注意写入一定要按顺序,从 0 写到 \(2^n - 1\);如果所有 valid bit 均为 1,那么就将对应 bit vector 对应的 block 替换了,同时,每一个 block 都将自己的 "I'm the first" bit 设置成其左侧 block 的 "I'm the first" bit 即可。
原理:我们的插入是有序的,从而保证了:从 "I'm the first" bit 为 1 的 block 开始,被插入的时候向右递增。
- 被插入时间最晚的 block,就是 "I'm the first" bit 为 1 的 block 左侧的 block。
Virtual Memory¶
我们并不会显式地在 memory 中额外划分一块,给 disk 当作 cache;而是通过虚拟内存的方式,将物理内存和硬盘上的内存有机结合了起来。
好处也很简单:
- 每一个应用程序占用的虚拟内存是连续的,但是物理内存未必
- 设置内存访问权限。有一些虚拟内存地址是 privilege 的
- 不管物理内存的实际大小,我们有了一个固定、规律的寻址空间
在任意时刻,虚拟页面的集合都分为三个不相交的子集:
- 未分配的 (Unallocated):VM 系统还未分配(或者创建)的页。未分配的块没有任何数据和它们相关联,因此也就不占用任何磁盘空间。
- 缓存的 (Cached):当前已缓存在物理内存中的已分配页。
- 未缓存的 (Uncached):未缓存在物理内存中的已分配页。
TLE¶
由于页表是存在内存里的,因此如果没有缓存的话,就会比较慢。我们这里可以加一个 TLE,进行缓存。具体详见 csapp。
简单来说,就是做下图中的替换:
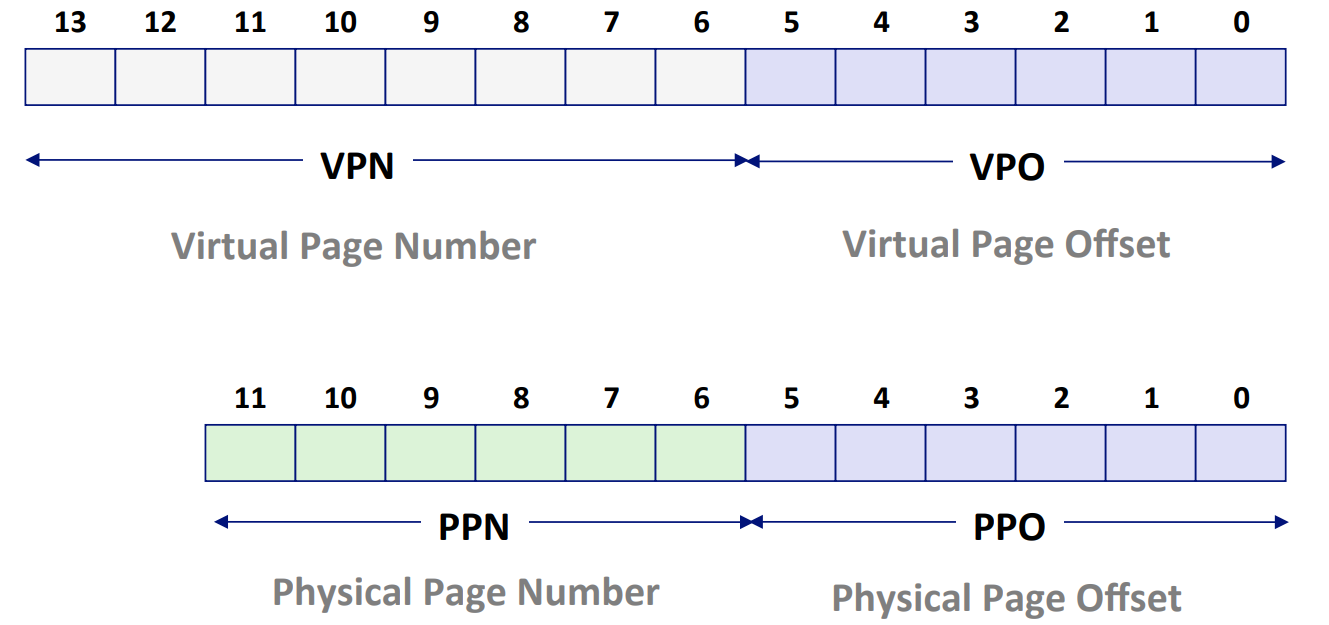
TLE Control Registers¶

其中:
- EPC: 记录我们在哪里使用
lw, sw指令产生了 TLB miss。这样好在取了 disk page 之后,再把这段指令执行完毕。 - Cause: 不赘述
- BadVAddr: 出问题的地址
- Index: 需要在哪里读取 TLB 的 entry
- Random: 就是一个随机数发生器。TLB 不采用 RLU 这样的策略,而是直接随机替换。
- EntryLo/Hi: 由于 virtual addressable space 远比 physical addressable space 要大,因此 virtual address 的地址相关的信息需要用 2 个 word 来记录,也就是说,需要用到两个寄存器。
- Context: 记录我们从内存中查到的 page table address 和 page number