18. Virtual Memory System
Lec 18: Virtual Memory System¶
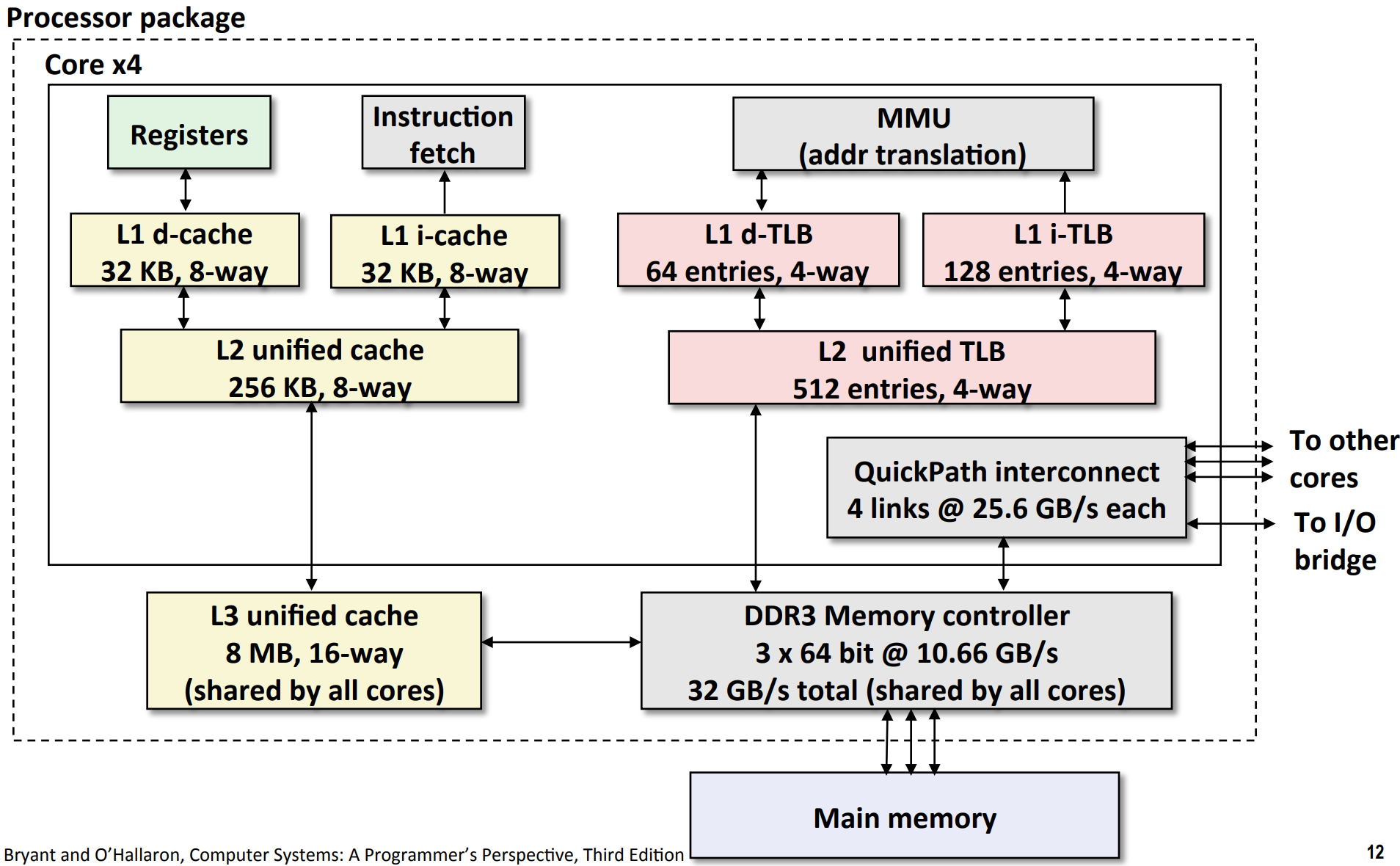
Intel Core i7 Memory System¶
End-to-end i7 memory translation¶
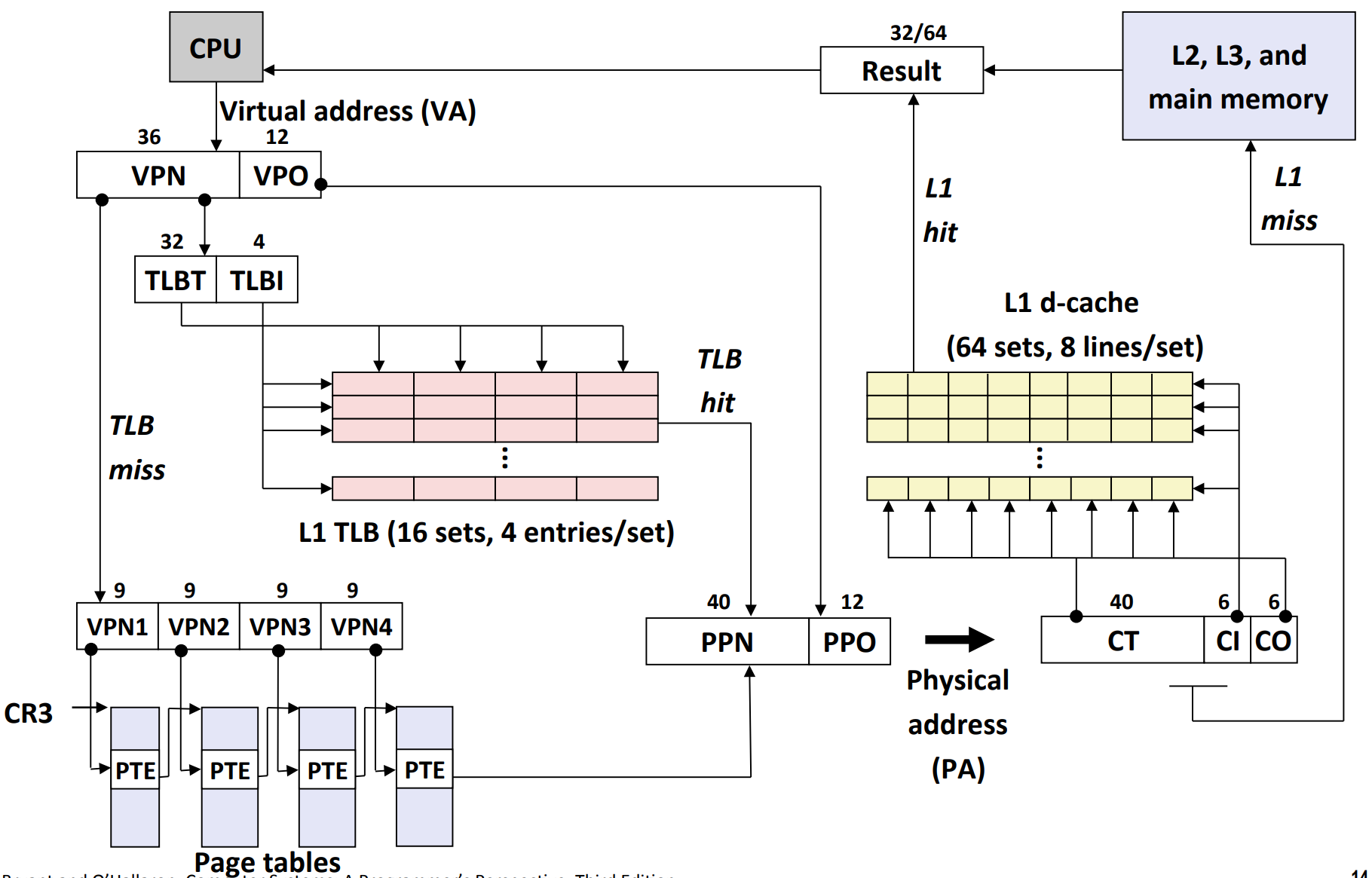
其中,
- 虚拟地址为 48 位。由于页大小为 4 KiB (\(2^{12}\) bits),因此 VPO 为 12 位,从而 VPN 为 36 位。
- 虚拟地址先在 TLB 中查询。
- 注意 TLB 有 64 entries,由于 4-way associative,因此有 16 sets。
- 从而,TLBI 有 4 位(\(2^4=16\))
- 从而,TLBT 有 32 位
- 如果 TLB miss,那么,就在 page table 中进行逐级查询
- 物理地址是 52 位。由于页大小为 4 KiB (\(2^{12}\) bits),因此 PPO 为 12 位,从而 PPN 为 40 位。
Table Entries¶
Core i7 Level 1-3 Page Table Entries

Core i7 Level 4 Page Table Entries

| Abbreviation | Description |
|---|---|
| P | Child page is present in memory (1) or not (0) |
| R/W | Read-only or read-write access permission for child page |
| U/S | User or supervisor mode access |
| WT | Write-through or write-back cache policy for this page |
| A | Reference bit (set by MMU on reads and writes, cleared by software) |
| PS | Page size either 4 KB or 4 MB (defined for Level 1 PTEs only) |
| D | Dirty bit (set by MMU on writes, cleared by software) |
| Page physical base address | 40 most significant bits of physical page address (forces pages to be 4KB aligned) |
| XD | Disable or enable instruction fetches from this page (modern systems use to protect the stack from code injection attack) |
Core i7 Page Table Translation¶
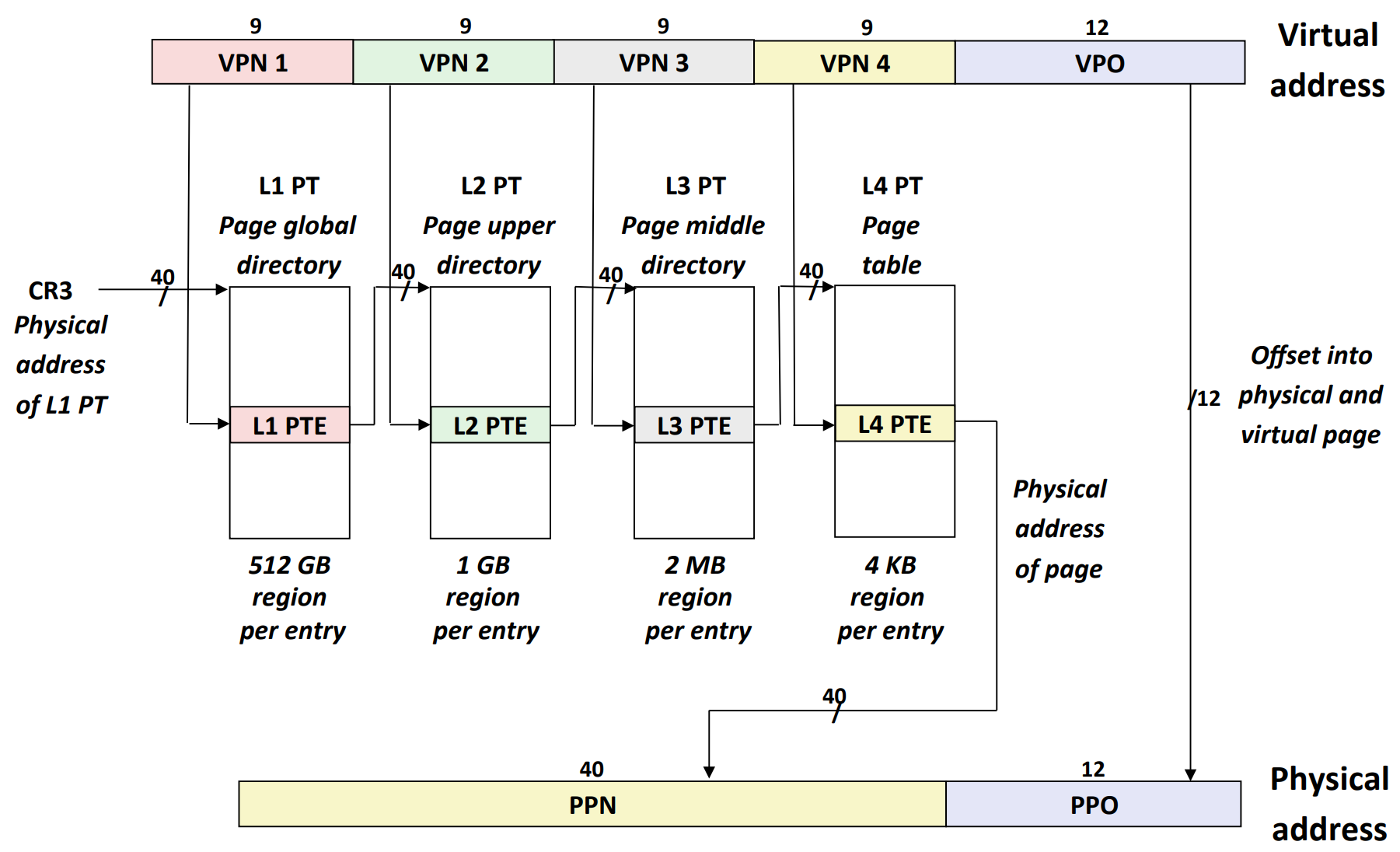
- 如果只有一个 page table,由于 entry size 为 64 bits,因此,就要制定 \(2^{36} * 64 ~\text{bits} \approx 4.4 ~\text{TB}2^{36} * 64 ~\text{bits} \approx 4.4 ~\text{TB}\) 的 page table,不现实
- 因此,我们制作 sub page table。第 2~4 级可以有任意多的 sub page table,第 1 级只能有一个。
- 每个 sub page table 的 entry 都指向一个 physical page。
- 而且,由于指针为 40 位,每级 VPN 为 9 位,每个 PTE 的大小为 \(64 \text{bits} = 8 \text{bytes} = 2^3 \text{bytes}\),因此,\(40 + 9 + 3 = 52\),正好是 1 页。
- 注意:每个 sub page table 都对应 1 physical page
- 另外,x86-64 也支持更大的页面,比如:
- 三级 PT with 21-bit offset:2 MiB page
- 二级 PT with 30-bit offset:1 GiB page
- CR3 是一个控制寄存器,储存(第 1 级)页表的起始地址。
Cute Trick for Speeding Up L1 Access¶
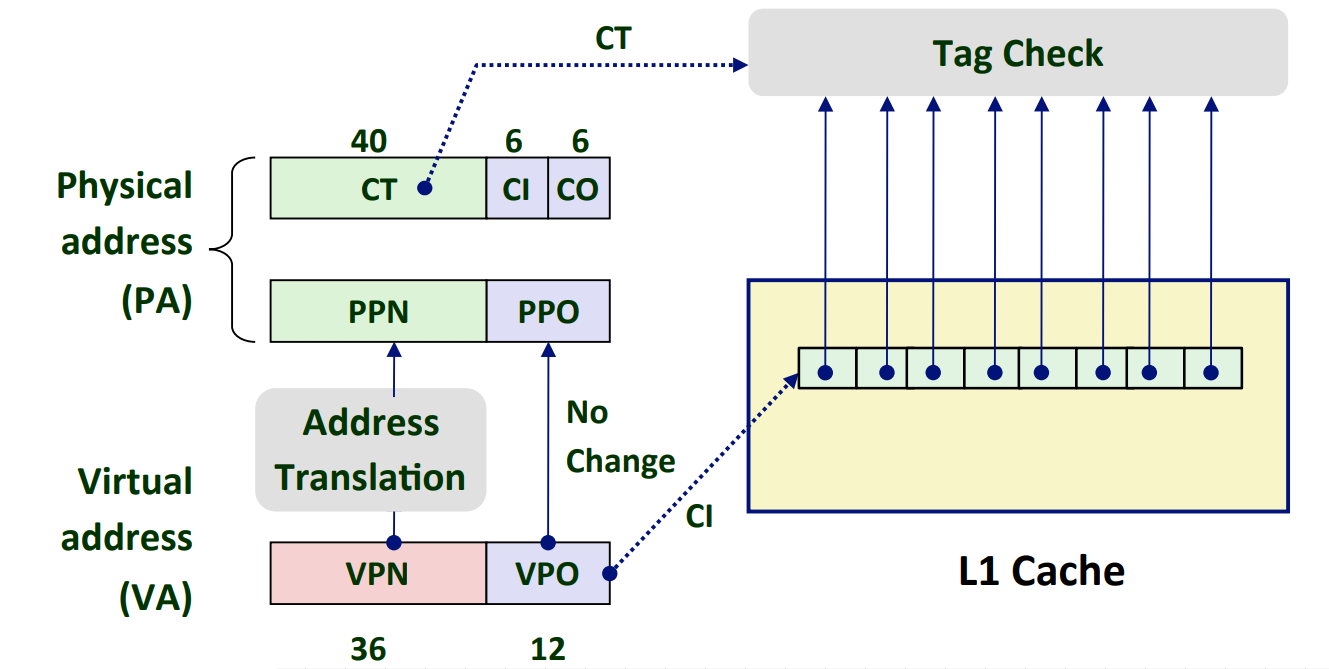
如图,本来 L1 Cache 需要的是 CI 和 CO。但是,由于 VPO = PPO,而且 PPO 与 CI+CO 对齐了。因此,我们可以在 CT 得到之前,先上传 VPO,使得 L1 Cache 与 Address Translation 并行,从而加快速度。
Virtual Address Space for Linux Process¶

如图,
- 图中的粗黑线,代表在 x86-64 isa 下,无法被访问的虚拟地址
- 由于 x86-64 isa 采用 sign extend,因此, kernel virtual memory 和 process virtual memory 各占上下一半,互相分隔。
- Kernel virtual memory 中,部分 virtual memory 是 shared,其它是 dedicated。
- 在 shared 中,部分是永远指向与虚拟地址相同的 physical memory 的(i.e. 上图中的 "physical memory"),其它是指向与 shared but not the same physical address。
Linux organize VM as a collection of "area"s¶
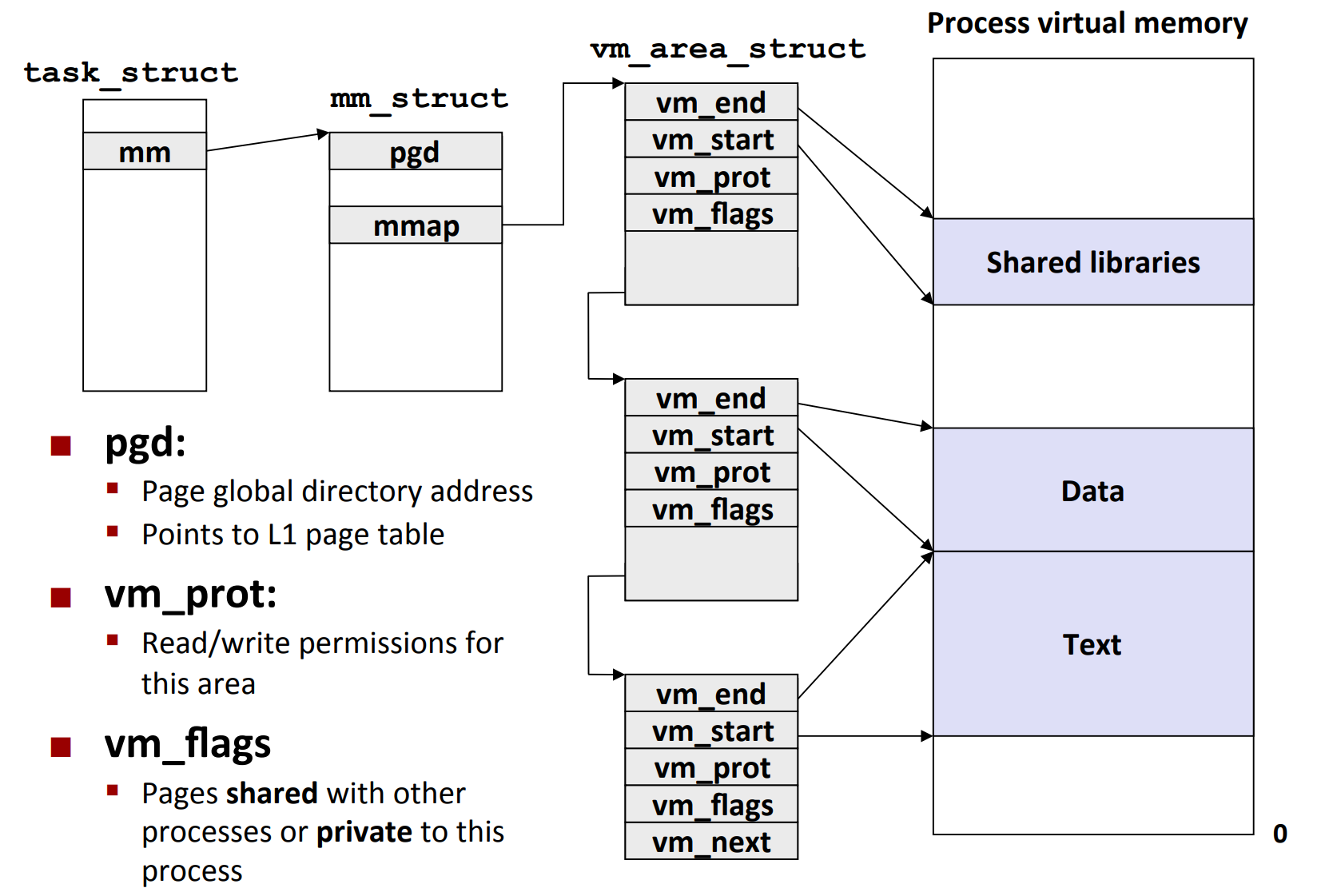
如图,对于每一个进程,都会有一个 mm_struct,其中,mmap 指向第一个 vm_area_struct。每个 vm_area_struct 对应一个内存区域。
- 注意:在真实的 OS 中,所有的
vm_area_struct会用红黑树等高效的数据结构进行存储。
Linux Page Fault Handling¶
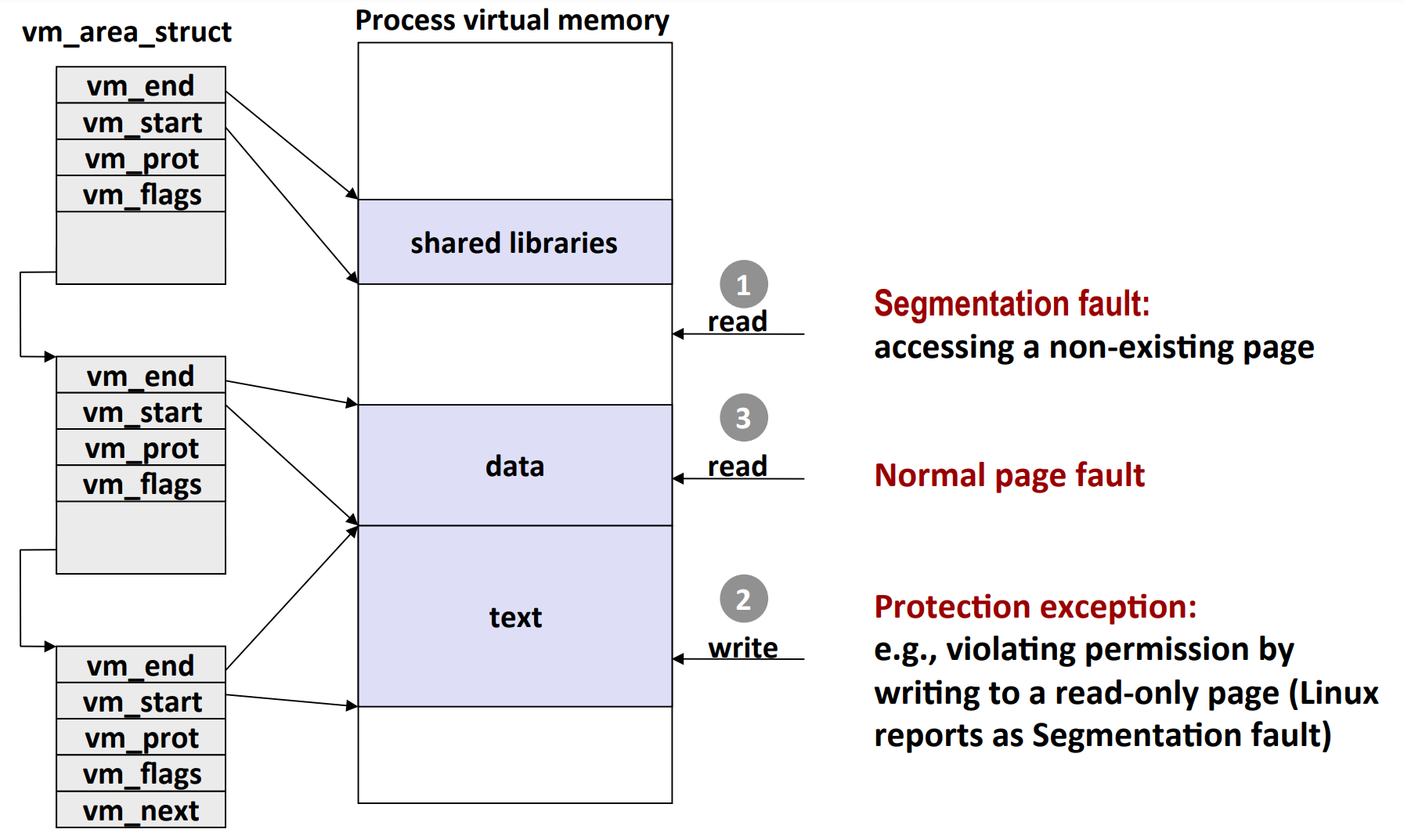
如图,
- 如果地址不再任何的 area 的 [start, end] 范围内,则就是 segmentation fault(访问不存在的 page)
- 如果写入只读的 area,那么就是 protection exception
- 其他情况下,可能是 normal page fault
Memory Mapping¶
VM areas initialized by associating them with disk objects.
- 这个过程被称为内存映射
- 为什么内存映射考虑的是”(常规/匿名)磁盘文件“?因为在系统层面,我们就是加载文件,所以我们只关心虚拟内存和文件的抽象对应关系。至于虚拟内存和物理内存/磁盘扇区的具体对应关系?那是硬件(MMU)的事情。
Area can be backed by (i.e.,get its initial values from):
- Regular file on disk (e.g.,an executable object file)
- Initial page bytes come from a section of a file
- Anonymous file (e.g.,nothing)
- First fault will allocate a physical page full of 0's(demand-zero page)
- Once the page is written to (dirtied), it is like any other page
Dirty pages are copied back and forth between memory and a special swap file.
Sharing Revisited: Shared Objects¶
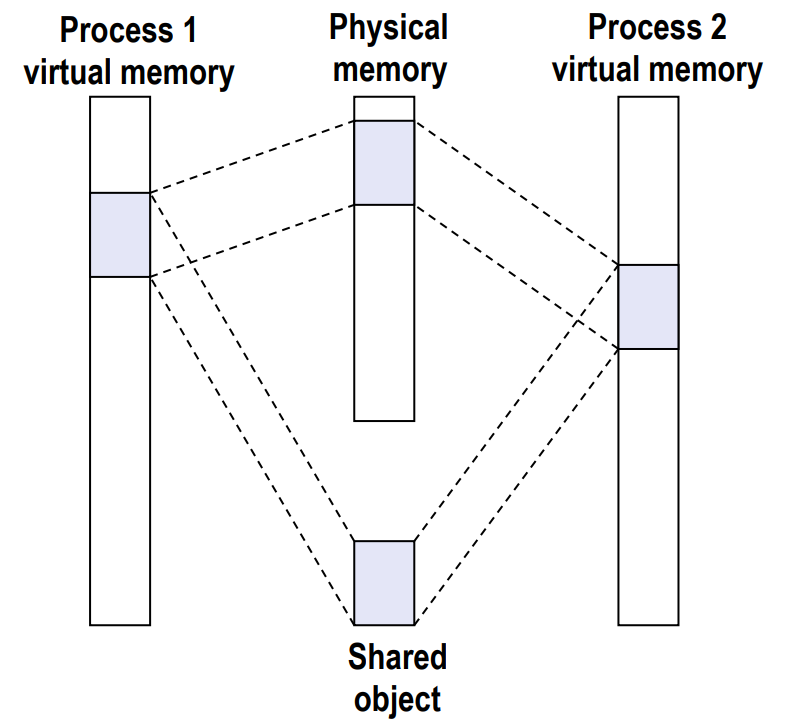
如图,两个进程共享一个 object。也就是说,无论读写,磁盘上的同一个 page 会缓存在同一段 memory 里。
Sharing Revisited: Copy-on-write (COW) Objects¶
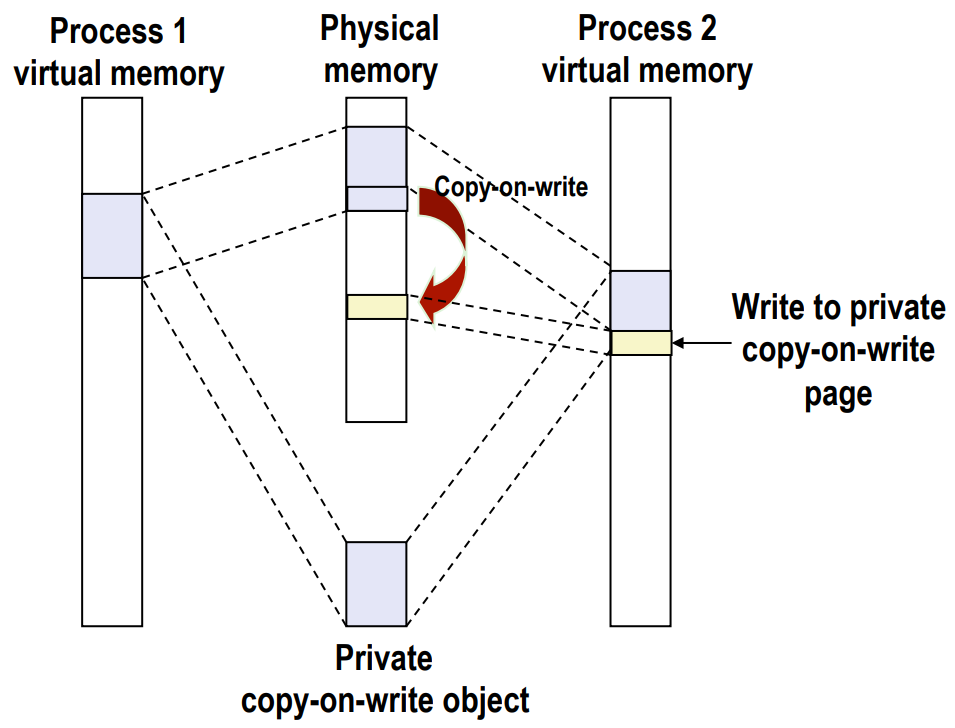
如图,
- Copy-on-write page 是
- private
- read-only
- 如果进程执行了写(write)操作。那么,就需要复制待更改的 page 到另外一个 page(图中从紫色小块复制到黄色小块),并对黄色小块进行改动
- 如果只是执行读(read)操作,那么就无需改变。
也就是说,如果只有读操作,磁盘上的同一个 page 会缓存在同一段 memory 里;只要包含了写操作,磁盘上的同一个 page 就会缓存在不同段的 memory 里。
Implementation¶
- Instruction writing to private page triggers protection fault.
- Handler creates new R/W page.
- Instruction restarts upon handler return.
In all, copying is deferred as long as possible!
fork revisited¶
Naive implementation of fork, as you can easily figure out, is incredibly expensive (i.e. you have to copy all those memory).
Implementation¶
- 将父进程的数据结构(i.e.
mm_struct,vm_area_struct以及 page table)复制到子进程 - 这些通常而言不会太多
- 将父进程和子进程的每一页(在 PTE 中)都标为 read-only
- 将父进程和子进程的每个
vm_area_struct都标为 COW
execve revisited¶
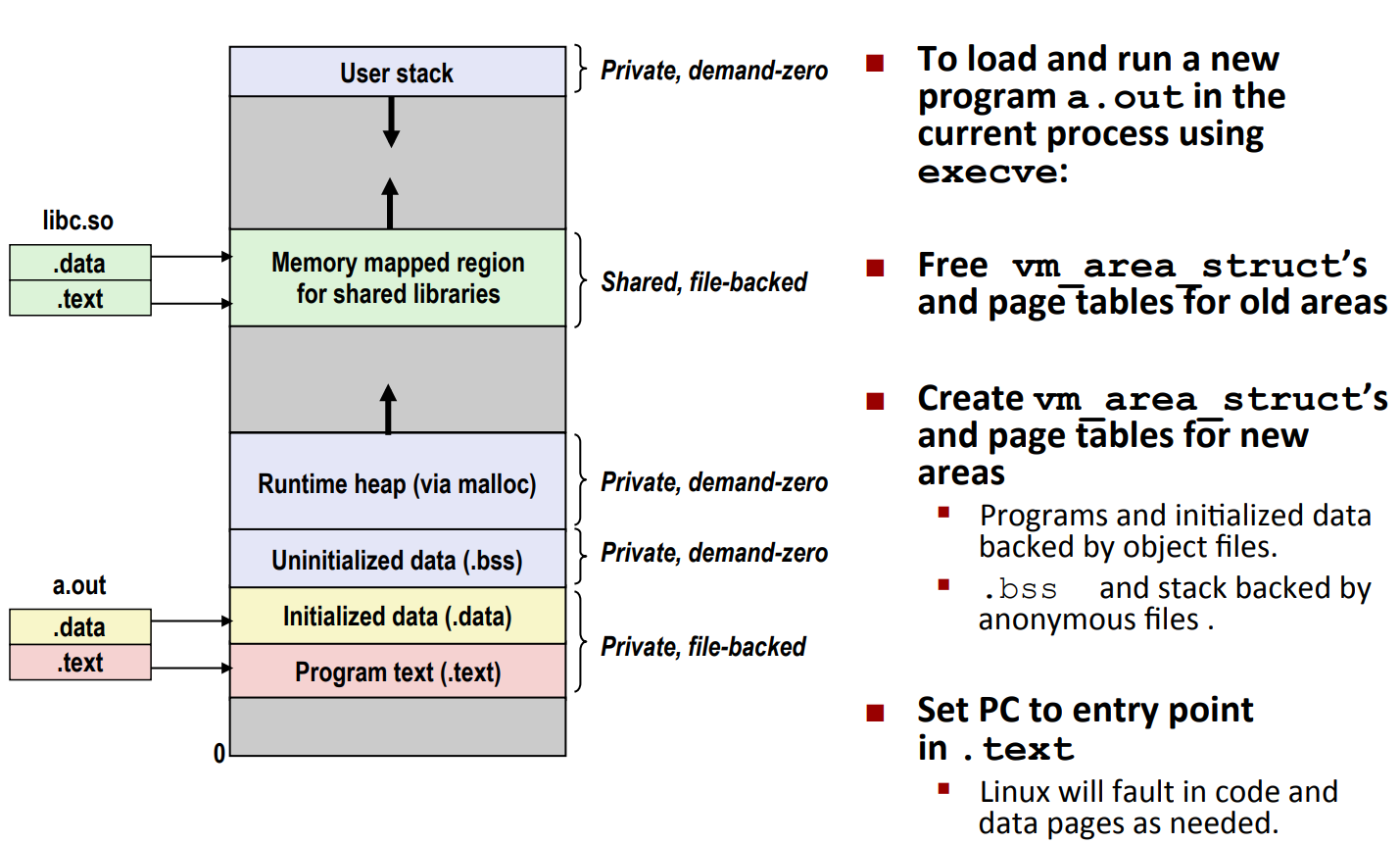
如图
- 首先清除旧的数据结构
- 然后创造新的数据结构
- 最后将
%rip指向.text的 entry point
注意:我们现在只建立了内存映射,而没有实际使用内存,从而非常 efficient。
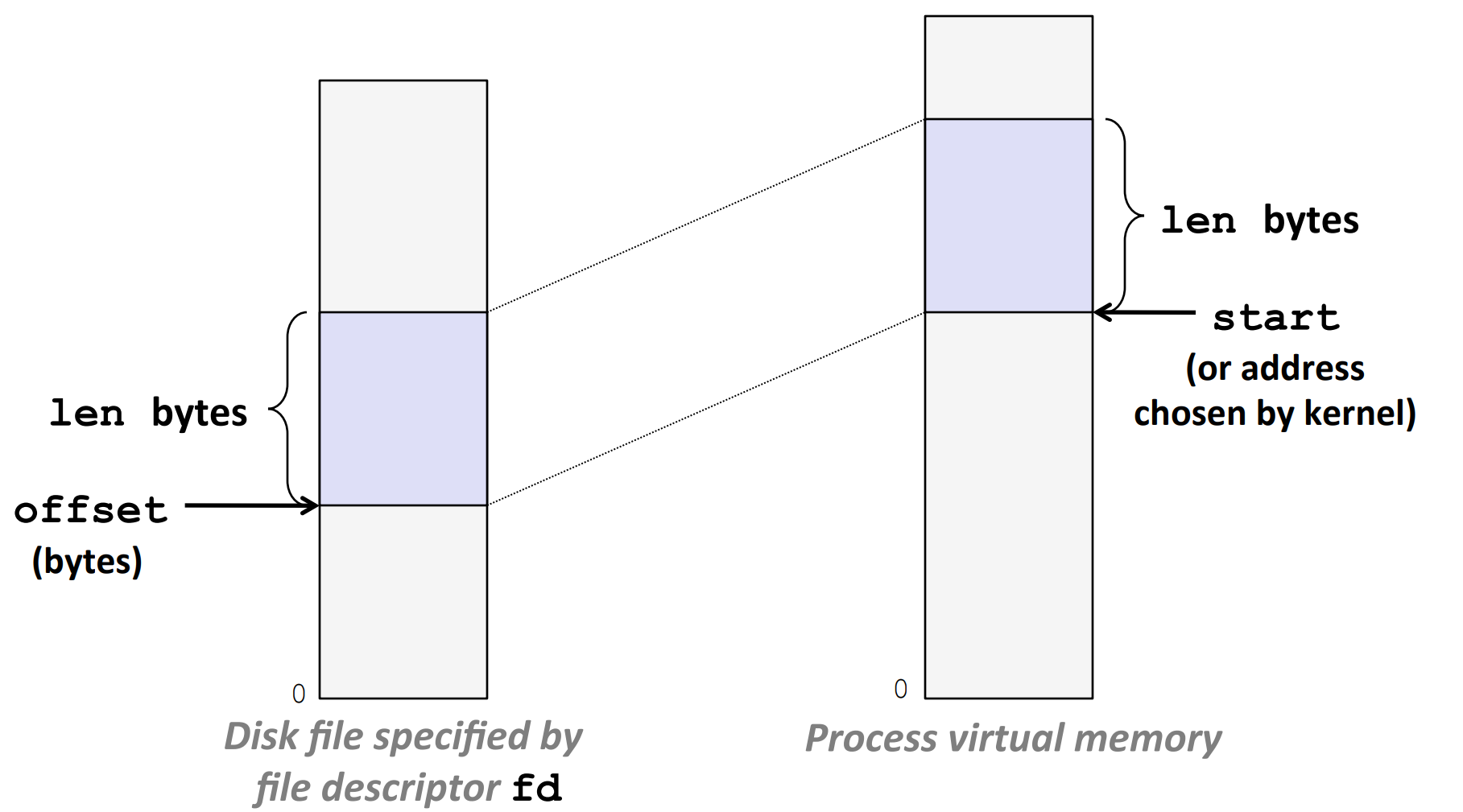
User-level memory mapping - mmap¶
##include <unistd.h>
##include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags,
int fd, off_t offset);
// 返回:若成功时则为指向映射区域的指针,若出错则为 MAP_FAILED(-1)。