2. Application Layer
Lec 2.0:应用层概述¶
网络应用的原理¶
- 网络应用协议的概念和实现方面
- 传输层的服务模型
- 客户-服务器模式
- 对等模式(peer-to-peer)
- 内容分发网络
网络应用的实例¶
- 互联网流行的应用层协议
- HTTP
- FTP
- SMTP / POP3 / IMAP
- DNS
编程¶
- 网络应用程序
- Socket API
Lec 2.1:应用层原理¶
网络应用的体系结构¶
可能的应用架构:
- 客户-服务器模式 (C/S:client/server)
- 对等模式 (P2P:Peer To Peer)
- 混合体:客户-服务器和对等体系结构
CS 体系结构¶
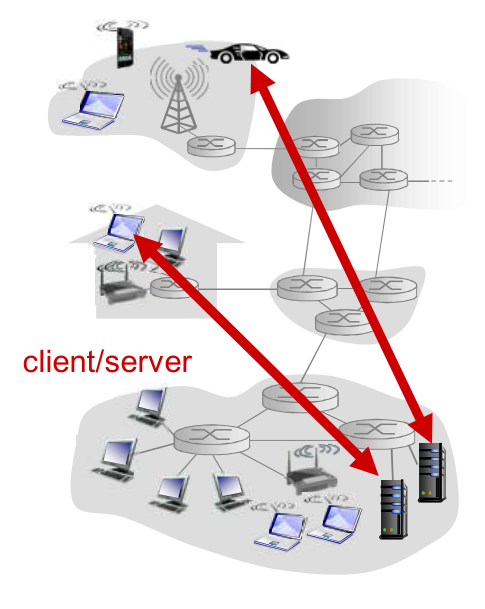
- 服务器
- 一直运行
- 固定 IP 地址和周知的端口号
- 扩展性差
- 客户端
- 主动与服务端通信
- i.e. 服务端先启动,客户端后通信
- 间歇性连接
- 可能是动态 IP
- 不直接与其他客户端通信
P2P 体系结构¶
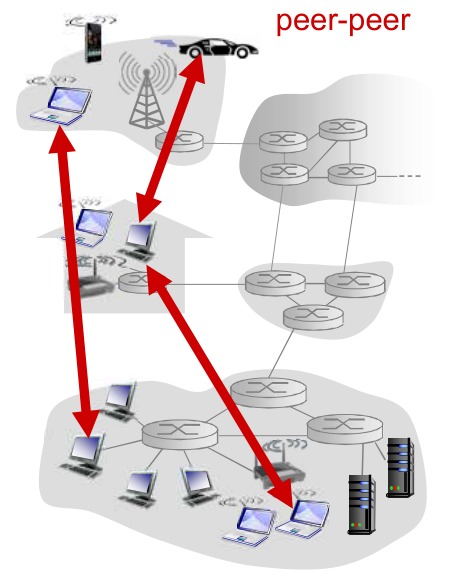
-
服务器/客户端
-
一直运行(几乎)没有一直运行的- 这使得 P2P 管理比较困难
- ~固定~可能改变的 IP 地址和周知的端口号
-
扩展性~差~强
-
主动与服务端通信 - 间歇性连接
- 可能是动态 IP
- ~不直接与其他~任意端系统之间可以通信
混合体系结构¶
Napster¶
- 文件搜索:集中
- 主机在中心服务器上注册其资源
-
主机向中心服务器查询资源位置
-
文件传输:P2P
- 任意Peer节点之间即时通信
即时通信¶
- 在线检测:集中
- 当用户上线时,向中心服务器注册其IP地址
-
用户与中心服务器联系,以找到其在线好友的位置
-
两个用户之间聊天:P2P
总体而言,就是 centralized register & lookup, decentralized communication。
进程通信¶
进程:在主机上运行的应用程序
- 在同一个主机内,可以直接采用进程间通信机制进行通信
- 比如 Linux 的管道1
- 不同主机,通过交换报文(Message)来通信
- 使用OS提供的通信服务
- 按照应用协议交换报文
- 借助传输层提供的服务
三个问题和解决方案¶
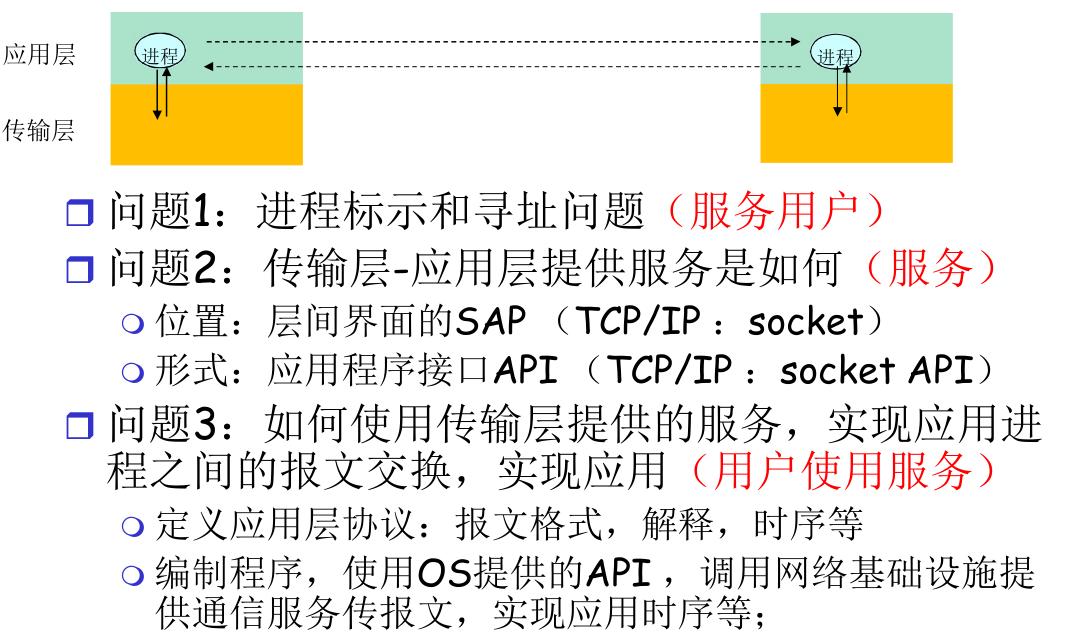
也就是
- 服务者如何区分和定位客户?
- 服务者应该如何服务?
- 客户如何使用服务?
问题一方案¶
- 进程为了接收报文,必须有一个标识 即:SAP
- 主机:唯一的 32 位地址
- 所采用的传输层协议:TCP or UDP?
- 端口号(用于区分同一主机上不同进程的标识)
- 一些知名端口号的例子
- HTTP: TCP 80
- Mail: TCP 25
- ftp: TCP 20,21
- 一个进程:用IP+port标示 -> 端节点
- 因此,本质上,一对主机进程之间的通信由 2 个端节点构成
问题二方案¶
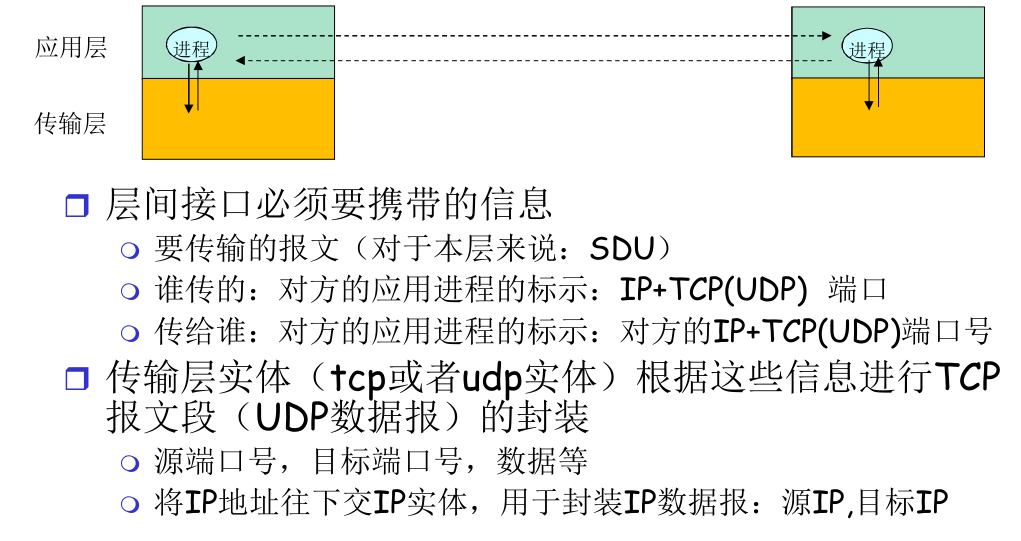
例子
- HTTP 协议将 http 的请求头、请求体等等封在 SDU 里
- HTTP 在层间接口 socket 处,通过 socket API,将控制信息 IDU 告知 TCP
- IDU 即:我是谁?TA 是谁?等等
- 从而,TCP 将这些信息以自己的方式,封装成 TCP header,并进一步下传
同时,由于 socket API 内容繁多,使用起来复杂麻烦,因此,我们就使用 socket 进行传输
-
也就是说:应用层在 SAP (也就是 port) 处,使用 Socket API 与传输层交流。由于 Socket API 比较繁琐,因此我们在 C 中使用封装的 Socket 进行调用。
-
在 Linux 上,(以 TCP socket 为例,)socket 建立之后,会返回一个文件描述符。我们只要向这个文件描述符传输数据就行
- (猜测)一个网络 IP + 端口,只能有一个 open file table entry
- 因此,比如
fork之后,可以有两个文件描述符指向同一个 entry - 但是,不能有两个进程两次调用 socket 指向同一个 ip:port
- 除非启用了
SO_REUSEPORT
- 除非启用了
对于 UDP socket,我们建立 socket 的时候,只用给自己的端口+IP,而无需事先给对方的。
- 等到每一次进行传输的时候,再给对方的端口+IP。
- 接收的时候,也要指定接收人的端口+IP。
Sidenote: 什么是 PDU, SDU, IDU, ICI¶
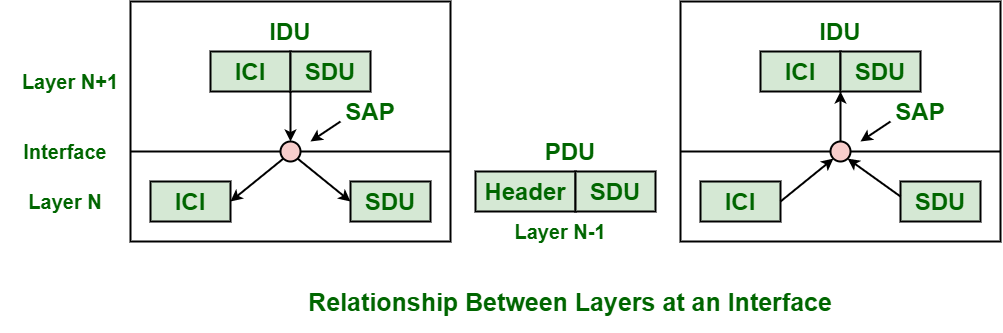
- PDU: 我方的第 N 层希望对方的第 N 层原原本本接收到的 unit
- IDU: 第 N 层传给第 (N-1) 层的 unit
- SDU: 携带数据的 unit
- ICI: 控制信息
- SAP: 第 N 层传给第 (N-1) 层的接口位置
可以这么认为:
- 我们希望传输到对方对等层的:PDU
- 我们需要向下层告知的:IDU
- 其中的数据部分:SDU
- 其中的信息部分:ICI
传输层应该向应用层提供怎样的服务?¶

数据丢失率、延迟、吞吐量、安全性
问题三方案¶
制定应用层协议
-
定义了:运行在不同瑞系统出的应用进程如何相互交换报文
-
交换的报文类型:请求和应答报文
-
各种报文类型的语法:报文中的各个字段及其描述
-
字段的语义:即字段取值的含义
-
进程何时、如何发送报文及对报文进行响应的规则
-
应用协议(应用层实体)仅仅是应用的一个组成部分
- 应用=界面+I/O+内部处理逻辑+应用协议
- Web应用:HTTP协议,web客户端,web服务器,HTML
Lec 2.2: Web & HTTP¶
Web 术语¶
- Web页:由一些对象组成
- 对象可以是HTML文件、JPEG图像、Java小程序、声音剪辑文件等
- Web页含有一个基本的HTML文件,该基本HTML文件又包含若干对象的引用(链接)
- 通过URL对每个对象进行引用
- 访问协议,用户名,口令字,端口等;
- URL格式:
Prot://user:[email protected]/someDept/pic.gif:port协议名 用户 口令 主机名 路径名 端口
HTTP¶
HTTP 本身无状态,其状态由 TCP 维护。
Web Server 有一个守护 socket,相当于经理;每出现一个请求,创建一个 socket 用于服务,相当于叫服务员。
HTTP 1.0 概况¶

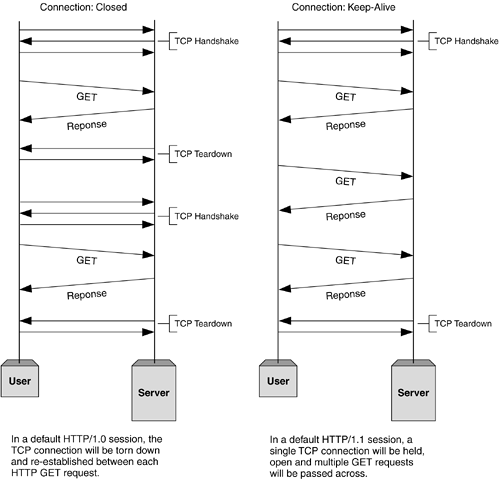
HTTP 1.1¶
对于 HTTP 1.1,HTTP 支持持久连接,如图所示:
HTTP 请求流程¶
假设用户输入 https://www.cs.cmu.edu/~pavlo/ 的 URL,对于 HTTP 1.0,请求流程如下:
- 客户端发起建立连接请求
- 服务端在 80 端口等待连接,接受连接并通知客户端
- HTTP客户端向TCP连接的套接字发送HTTP请求报文,报文表示客户端需要对象
~pavlo - HTTP服务器接收到请求报文,检索出被请求的对象,将对象封装在一个响应报文,并通过其套接字向客户端发送
- HTTP 关闭 TCP 连接
- HTTP客户端收到包含html文件的响应报文,并显示html。然后对html文件进行检查,找到所有的引用对象
- 对于每个引用对象,递归重复 1-6 步
因此,对于 HTTP 1.0,一次请求,需要2 个 RTT + 对象传输时间。
对于 HTTP 1.1,在建立连接之后,会进行多次 HTTP Request。而且,会以流水线的方式,进行 HTTP 请求,即:如果有多个对象需要请求,那么就会同时请求。
HTTP 请求格式¶
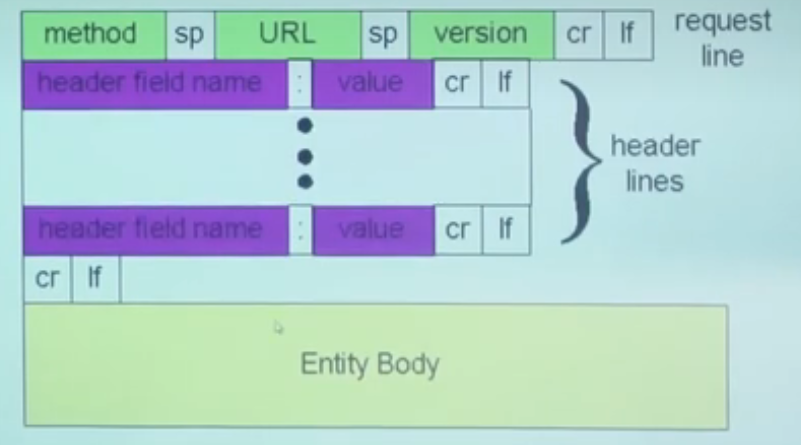
注意:request line 和 header line 都必须使用 ASCII 编码,不过 entity body 无需。
HTTP 状态保持:Cookie¶
为了以某种等价的形式保持 HTTP 的状态,我们需要用到 cookie。
Cookie 中的项,一般都会被保存在服务端的数据库里。从而,服务器可以用于 cookie 来 identify user。
Web 缓存¶
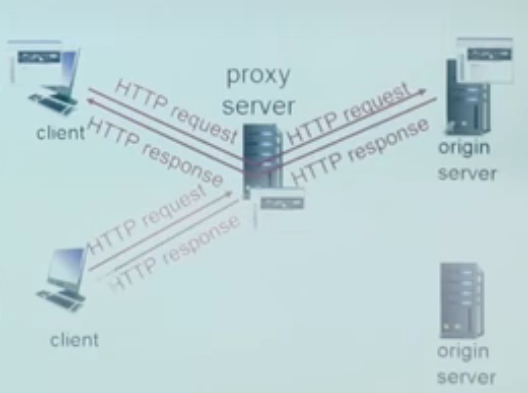
由于同一个地区的人的访问趋同性,内容访问的时间局部性很好,因此通过设立 Web 缓存,可以有效优化网络。
Web 缓存通常由 ISP 安装(大学、公司、居民区 ISP),用于
- 降低响应延迟
- 减小流量
- 由于互联网大量使用缓存,较弱的 ICP 也能提供服务
至于如何判定缓存内容是否改名,Web 服务器会向 server 发一个 HTTP 请求,但是携带一个键为 If-Modified-Since header,值为 Last-Modified-Time 的信息。
Lec 2.3: FTP (File Transport Protocol)¶
(主动模式下的)FTP 连接过程:
- 客户端打开一个随机的端口(端口号大于1024,在这里,我们称它为x),同时一个FTP进程连接至服务器的21号命令端口。此时,该tcp连接的来源地端口为客户端指定的随机端口x,目的地端口(远程端口)为服务器上的21号端口。
- 客户端开始监听端口(x+1),同时向服务器发送一个端口命令(通过服务器的21号命令端口),此命令告诉服务器客户端正在监听的端口号并且已准备好从此端口接收数据。这个端口就是我们所知的数据端口。
- 服务器打开20号源端口并且创建和客户端数据端口的连接。此时,来源地的端口为20,远程数据(目的地)端口为(x+1)。
- 客户端通过本地的数据端口创建一个和服务器20号端口的连接,然后向服务器发送一个应答,告诉服务器它已经创建好了一个连接。
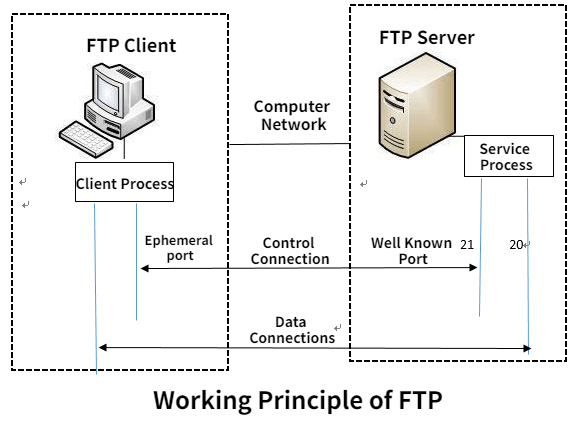
FTP 显然是有状态的(应用层)协议。服务器和客户端都维持着通信状态。
FTP 控制命令&返回码示例¶

与 HTTP 区别¶
- 有状态
- 控制命令和数据传输分别在两个 TCP 连接上
Lec 2.4: Email¶
3个主要组成部分:
- 用户代理
- 邮件服务器
- 简单邮件传输协议:SMTP
- 电子邮件应用分为发送端和接收端:
- 邮件服务器之间传输以及用户代理传输给邮件服务器,就是 SMTP 一种
- 邮件服务器传输给用户代理,可以是 POP3, IMAP, HTTP
用户代理¶
电子邮件应用的用户代理,就是电子邮件客户端(如 Outlook 等等)。
- 就像 HTTP 的用户代理,就是 Web 浏览器;FTP 的用户代理,就是 FTP 客户端
- “代理”的意思就是:这个东西代替你去完成一些事情,如 Web 浏览器代替用户去发送 HTTP 请求。
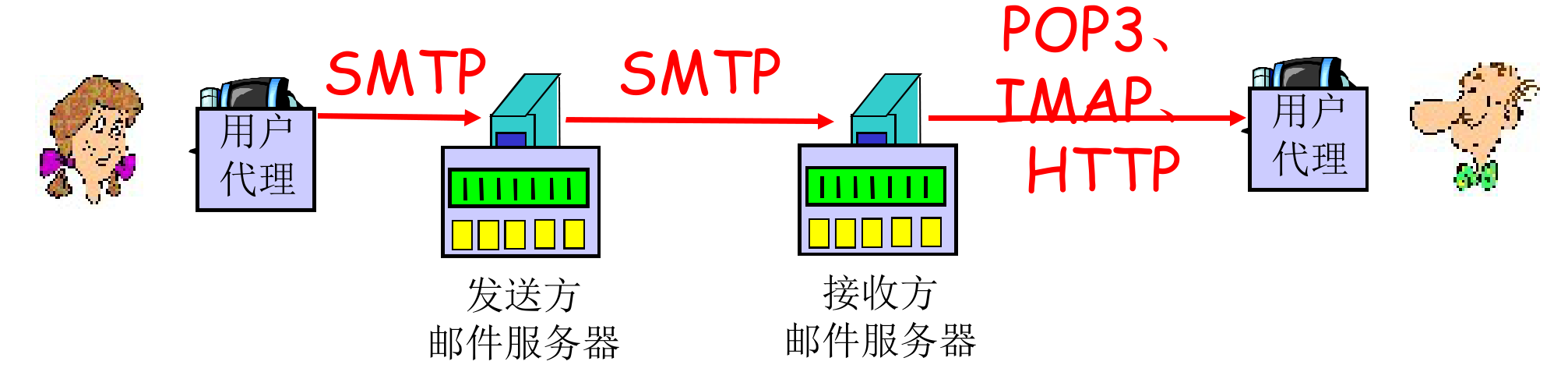
邮件服务器¶
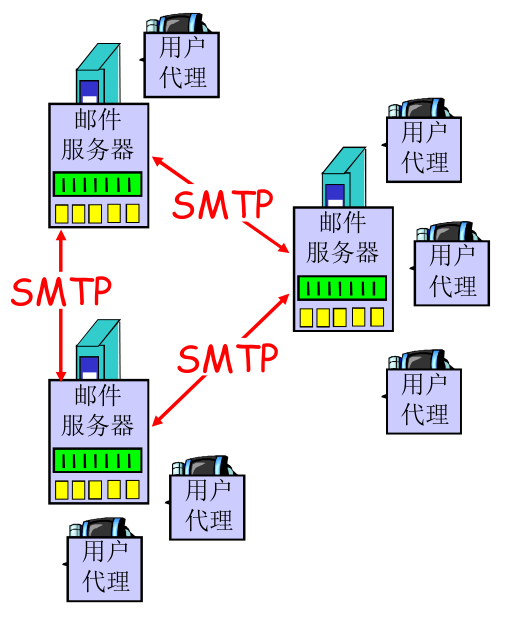
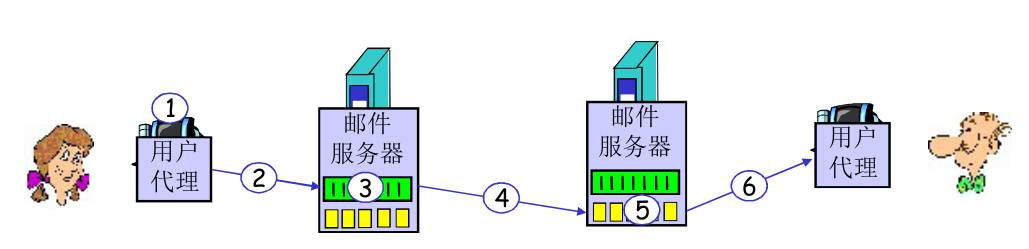
如上图和下图,
- 用户代理传输到邮件服务器以及邮件服务器之间通信,使用 SMTP 进行
- 对应下图 (2), (4)
- 邮件服务器收到了信件之后,会将其加入自己的队列,逐一传输到对应用户的 mailbox 里
- 用户使用 POP3, IMAP 或 HTTP 从邮件服务器中取回信件
- 对应下图 (6)
SMTP¶
SMTP via telnet¶
╭─root@mtdickens /home/mtdickens
╰─➤ telnet smtp.zju.edu.cn 25 1 ↵
Trying 61.164.42.155...
Connected to mail.zju.edu.cn.
Escape character is '^]'.
220 zju.edu.cn Anti-spam GT for Coremail System (mispb-4df6dc2c-e274-4d1c-b502-72c5c3dfa9ce-zj.edu.cn[20230316])
EHLO smtp.zju.edu.cn
250-mail
250-PIPELINING
250-AUTH LOGIN PLAIN
250-AUTH=LOGIN PLAIN
250-coremail 1U3r2xKj7kG0xkI17xGrU7I0s8FY2U3Uj8Cz28x1UUUUU7Ic2I0Y2UracVUbb0I7xC2jI0I4UJUUUU81IkIcUJUUUU8=
250-STARTTLS
250-SMTPUTF8
250 8BITMIME
AUTH LOGIN
334 dXNlcm5hbWU6
<my username in base64>
334 UGFzc3dvcmQ6
<my password in base64>
235 Authentication successful
MAIL FROM: <[email protected]>
553 Mail from must equal authorized user
MAIL FROM: <[email protected]>
250 Mail OK
RCPT TO: <[email protected]>
250 Mail OK
DATA
354 End data with <CR><LF>.<CR><LF>
From: [email protected]
To: [email protected]
Subject: Test Sending Email with Telnet
Hello! How's everything going?
I'm [email protected].
.
250 Mail OK queued as cC_KCgBnbjkC4eJldi_KAQ--.11653S3
QUIT
221 Bye
Connection closed by foreign host.
如上,我输入的每一条命令前面,都加上了一个 tab(原本没有 tab),从而与返回信息区分。
注意:
- SMTP 连接是持久连接,只有在 client 发送了 QUIT 之后,服务器才会断开连接。
- SMTP要求报文(首部 和主体)为7位ASCII编码
- b/c of the ASCII tradition
- SMTP服务器使用
<CRLF>.<CRLF>决定报文的尾部
SMTP 报文格式¶
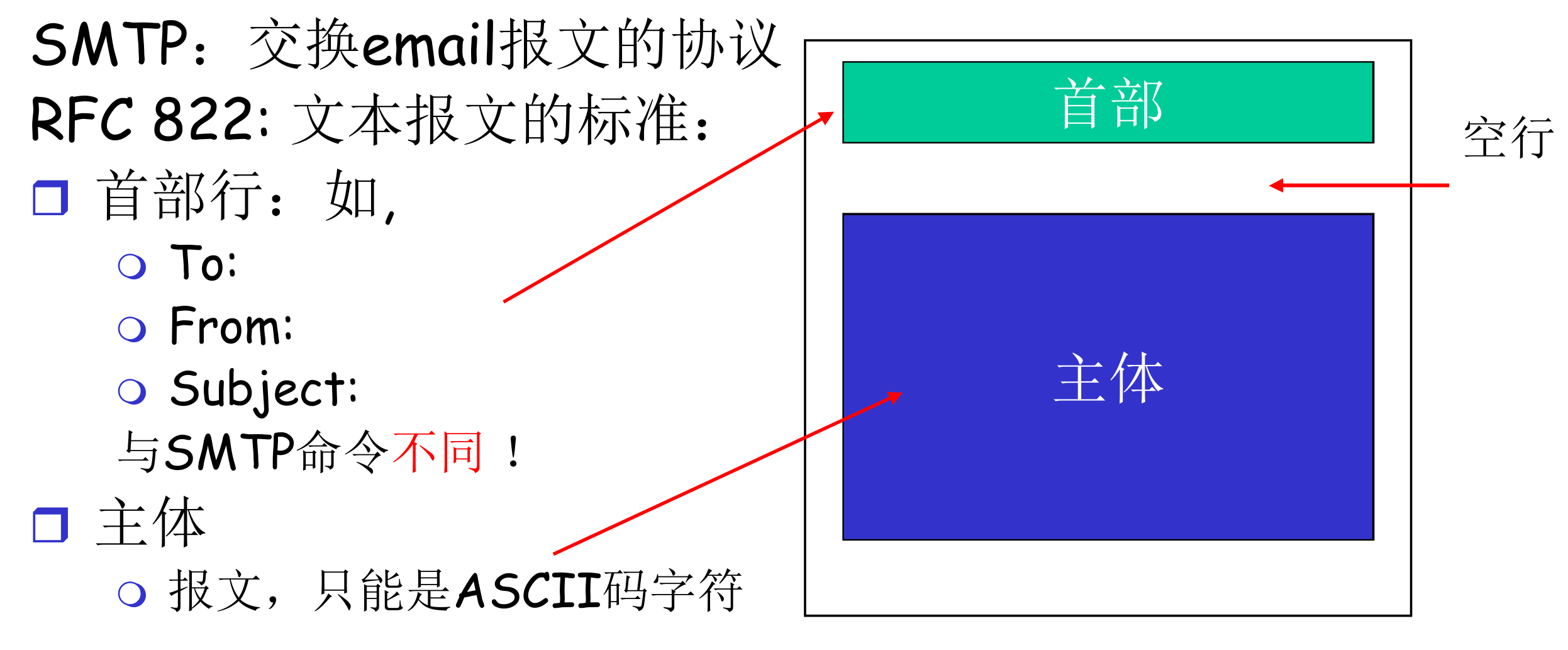
SMTP 报文格式如上,其中,主体中可以有多个对象(与 HTTP 不一样),比如同时有文本、附件等等。
SMTP extended encoding¶
由于 SMTP 只支持 ASCII,因此,多媒体文件和非英语语言,就需要用到 MIME (RFC 2045, 2056) via base64 encoding:
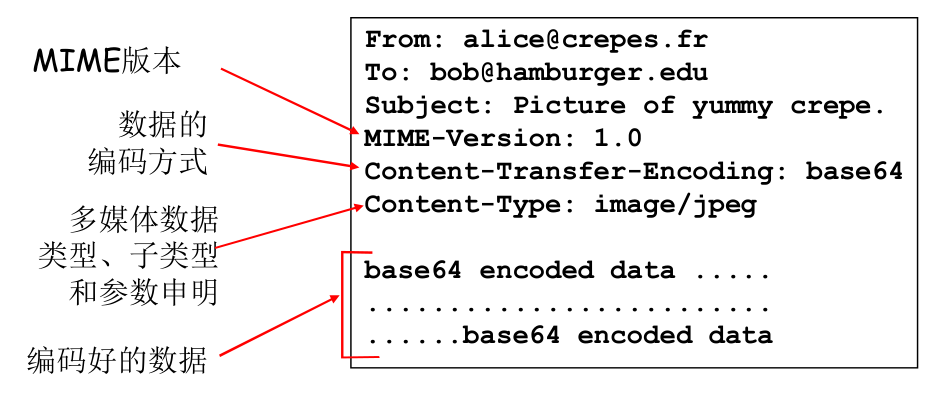
POP3, IMAP 和 HTTP¶
- SMTP: 传送到接收方的邮件服务器
- 邮件访问协议:
- POP: 邮局访问协议(Post Office Protocol)[RFC 1939]
- 用户身份确认 (代理<-->服务器) 并下载
- IMAP: Internet 邮件访问协议(Internet Mail Access Protocol)[RFC 1730]
- 更多特性 (更复杂)
- e.g. 允许用户远程维护目录等等
- 在服务器上处理存储的报文
- HTTP: Hotmail, Yahoo! Mail等
- 方便
POP3 via telnet¶

POP3 vs IMAP¶
- POP3会话是无状态的
- 下载并删除模式:
- 在这种模式下,邮件被下载到客户端后会立即从服务器上删除。这意味着邮件只存在于客户端,服务器上不再保留邮件的副本。
- 这种模式下,POP3会话是无状态的,因为每次连接到服务器时,都会下载所有的邮件并删除服务器上的副本,不会保留任何关于会话状态的信息。
- 下载并保留模式:
- 在这种模式下,邮件被下载到客户端后不会立即从服务器上删除,而是等到客户端主动删除或者按照服务器上的规定时间自动删除。
- 这种模式下,POP3会话仍然可以看作是无状态的,因为服务器不需要跟踪每个会话的状态,只有客户端和服务器之间的简单交互。
- IMAP会话是有状态的,因为服务器会记住客户端的会话状态。这意味着客户端可以在多次连接之间保持对服务器的持续连接,并且服务器会跟踪邮件的状态和文件夹结构等信息。
Lec 2.5: DNS¶
三个问题¶
- 问题1:
- 如何命名设备:
- 用有意义的字符串:好记,便于人类使用
- 解决一个平面命名的重名问题:层次化命名
- 如何命名设备:
- 问题2:
- 如何完成名字到IP地址的转换:
- 分布式的数据库维护和响应名字查询
- 如何完成名字到IP地址的转换:
- 问题3:
- 如何维护:增加或者删除一个域,需要在域名系统中做哪些工作
DNS 的总体思路和目标¶
总体思路
- (针对问题 1)分层的、基于 domain 的命名机制
- (针对问题 2)若干分布式的数据库完成 hostname to IP conversion
- (针对问题 2)运行在 UDP 53 端口的应用服务
- 核心的 Internet 功能,但以应用层协议实现,从而得以在网络边缘处理复杂性
目标
- 主要目标:name/IP translate (A/AAAA)
- 其他目的
- host aliasing (CNAME)
- 比如,很多主机的规范名和编号、机房、地址等等有关,因此呈现给客户的时候,我们需要用到规范名字
- mail server aliasing (MX)
- 比如域名邮箱,就需要使用 MX,将自己的域名指向 server 的(规范)域名。从而,如果某人发邮件给你,就可以发到对应的 server 上去
- 负载均衡
DNS 名字空间¶
域名的分层¶
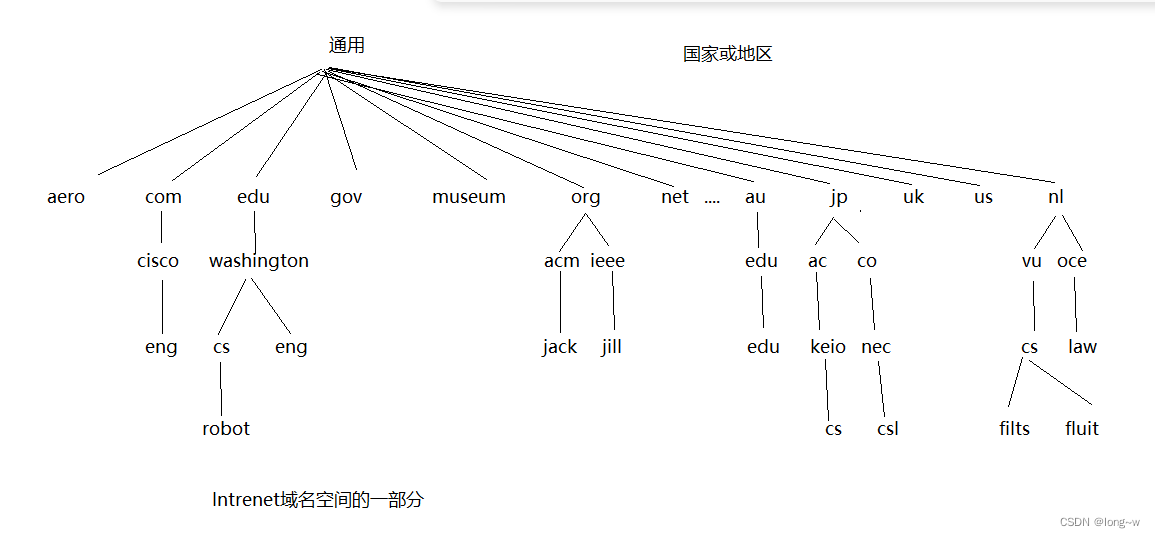
如图,这就是分层明明,形如 jp, net 被称为顶级域,ac.jp, google.com 被称为二级域,诸如此类。
域名的管理¶
- 域名的管理
- 一个域管理其下的子域 .jp 被划分为 ac.jp co.jp .cn 被划分为 edu.cn com.cn
- 创建一个新的域,必须征得它所属域的同意域与物理网络无关
- 域遵从组织界限,而不是物理网络
- 一个域的主机可以不在一个网络
- 一个网络的主机不一定在一个域。域的划分是逻辑的,而不是物理的
分布式查询¶
域名被分为不相交的域(zone)。
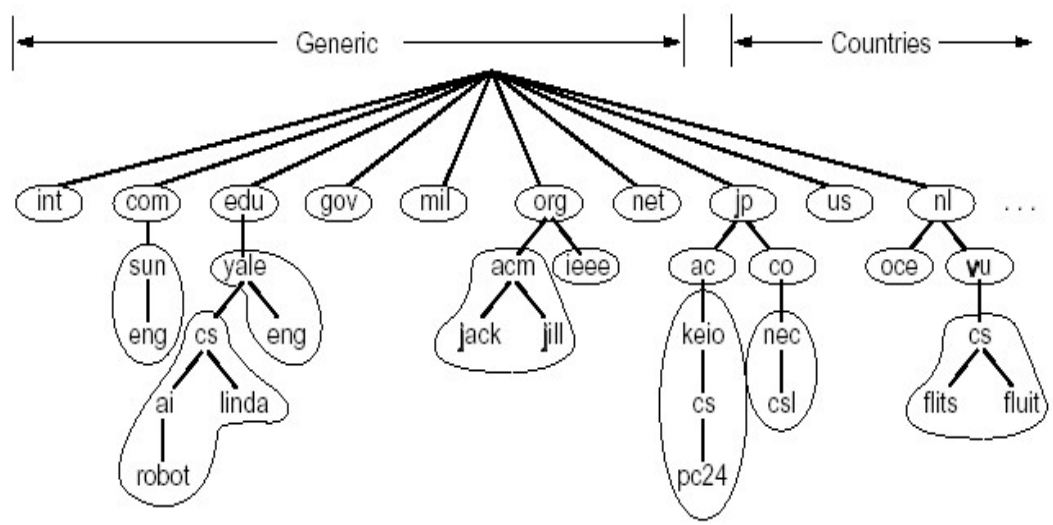
如图,由于耶鲁计算机系下面域名众多,因此独成一 zone(*.cs.yale.edu)。其它的 *.yale.edu(其中不含 *cs.yale.edu)又成一个 zone。
每个 zone 都有权威名字服务器,负责记录 zone 里面所有域名的相关信息(稍后介绍)。
而 zone 之上的节点,就是 x-LD (x- Level Domain) Nameserver。它们负责记录 (x+1)-LD 和 (x+1) 层的权威名字服务器的地址。
- 注意:x-LD 同时也是权威名字服务器,因为它总要记录自己的 x-LD 的 NS 记录。比如
- 权威名字服务器:
eu.org记录着诸如nic.eu.org,eu.org,www.eu.org的各种记录 - 2LD:
eu.org记录着其它的*.eu.org的权威名字服务器的地址- 比如,
mtds.eu.org的地址就是 Cloudflare 的服务器
- 比如,
资源记录¶

其中,对于权威服务器上的 RR,TTL 是无限大,而对于非权威的,RR 只不过是缓存,因此 TTL 就是一个特定的有限值,过了时间就删除,以确保缓存一致性。
查询流程¶
如下图,
- 应用程序向 resolver application 发送一个请求
- resolver 将这个请求以 UDP 的方式发送给 LNS
- LNS 进一步进行查询(稍后会写),并返回 response
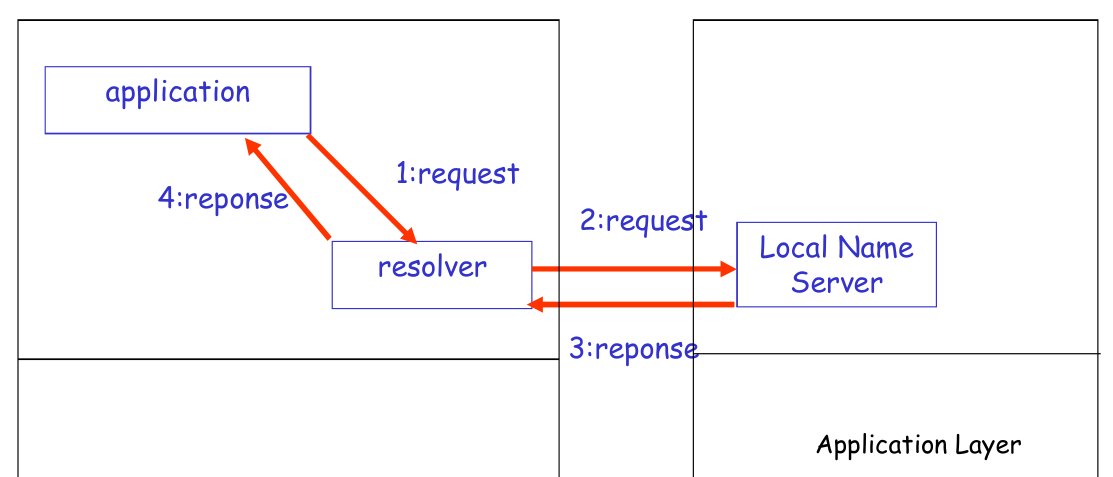
Local Name Server¶
- 并不严格属于层次结构
- 一般而言,每个 ISP(居民区、公司、大学)都有一个 LNS
- 起到代理的作用,将查询转发到层次结构中
查询时,
- 如果目标名字在 LNS 内部,那么就直接返回
- Case 1: 查询的名字在该区域内部
- Case 2: 缓存
- 否则,就联系根服务器,顺着根-TLD-SLD-...,一直找到权威名字服务器
递归查询、迭代查询¶
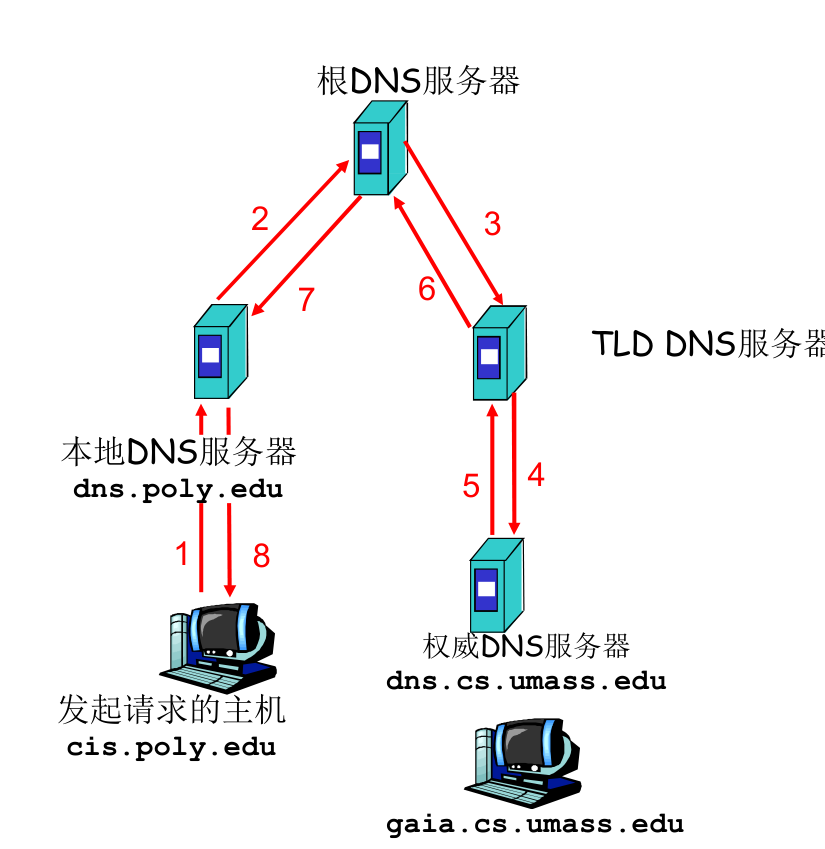
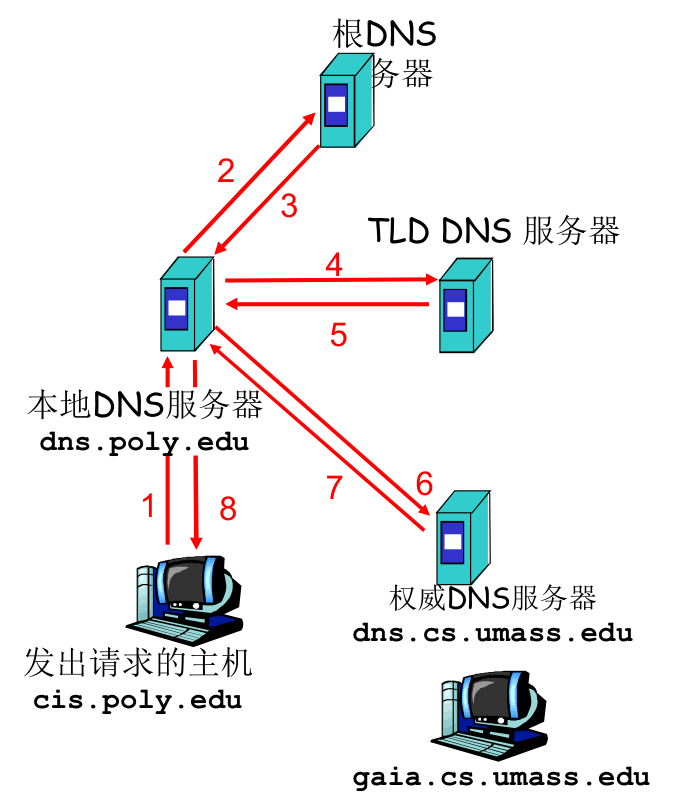
递归查询(如左图)会给根 DNS 服务器造成巨大压力(需要返回整个 DNS 数据包)。
因此,目前的解决方案,就是
- TLD、权威服务器,均使用迭代查询(如右图,只需返回下级 DNS 服务器的 IP 地址)。
- 至于像 1.1.1.1, 8.8.8.8 这样的公共/私人 DNS 服务器,它们是递归解析器(帮你直接查完,和 LNS 做的工作一样)
DNS 协议、报文¶

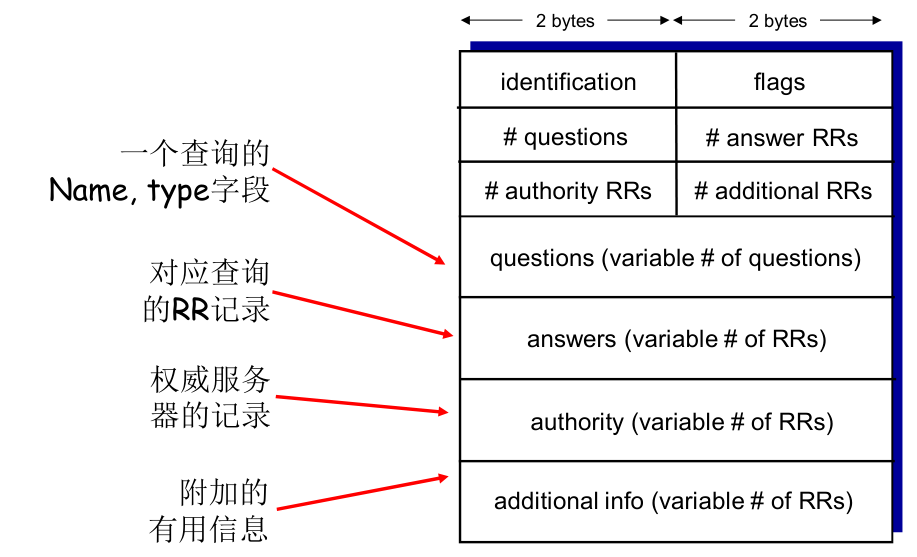
增删域名¶
比如,你希望在 Cloudflare 上托管 mtds.eu.org,那么,你把以下两种记录交给 eu.org 的 TLD 服务器:
(mtds.eu.org, PORTER.NS.CLOUDFLARE.COM, NS),(mtds.eu.org, ARON.NS.CLOUDFLARE.COM, NS)(PORTER.NS.CLOUDFLARE.COM, 108.162.195.243, A), etc
从而,eu.org 的 2LD 名字服务器就知道了 mtds.eu.org 的 3LD 或权威名字服务器是什么。
- 本例中,是权威名字服务器,
ARON.NS.CLOUDFLARE.COM知晓关于*.mtds.eu.org的一切
注意:eu.org 并不会直接在你查询 mtds.eu.org, #NULL, IN, NS, #NULL 的时候,返回给你 mtds.eu.org 的 NS 记录。它还是会通过 authority 告知你,让你去 mtds.eu.org 的 权威域名服务器上去查。
从而,当迭代查询 mtds.eu.org 的时候,如下:
- 根服务器让你去
.orgT(op)LD 名字服务器 - 不过,实际上,LNS 大多有 TLD、2LD 的缓存,因此不一定从 root 开始查询
.orgTLD 名字服务器让你去.eu.org2LD 名字服务器.eu.org2LD 名字服务器让你去mtds.eu.org权威名字服务器- 然后,
ARON.NS.CLOUDFLARE.COM就可以给你正确的答复
Lec 2.6: P2P 应用¶
引入:文件分发时间¶
对于 C/S 模式,文件分发时间等于 $$ D_{C-S} \geq \max{NF/u_s, F/d_{min}} $$ 其中,\(N\) 就是用户数量,\(u_s\) 就是服务器最大上载速率,\(d_{min}\) 就是用户链路中的瓶颈。
当 \(N\) 很大的时候,服务器的服务能力会很快下降。因此,我们需要 P2P 模式。
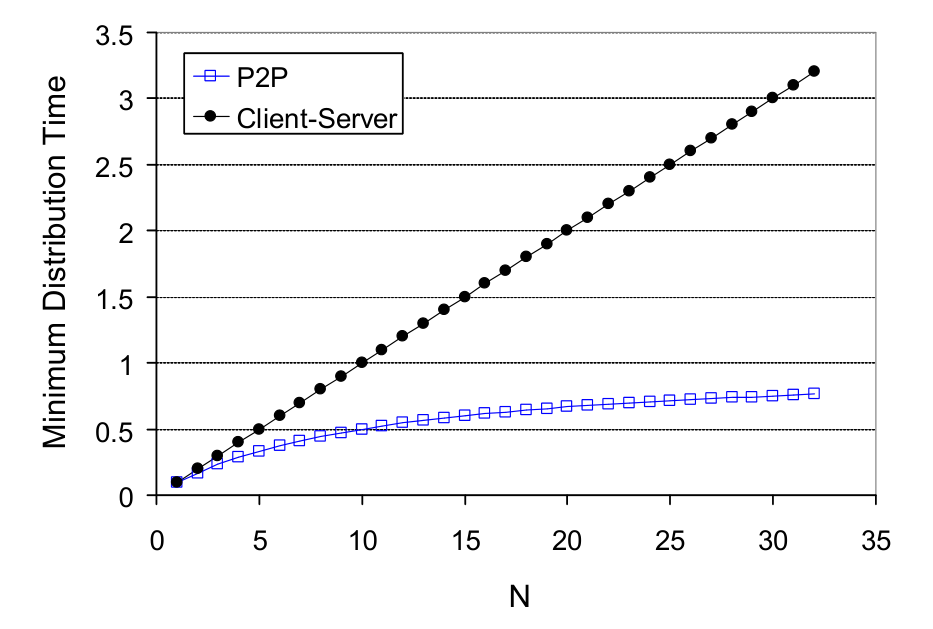
纯 P2P 模式¶
文件分发时间,利用简单模型,理论上可以是: $$ D_{P2P} \geq \max{\frac {NF} {u_s + \sum_{i=1}^N u_i}, F/d_{min}, F/u_s} $$ 其中,
- 最后一项是服务器的发送速率
- 中间一项是接受速率
- 第一项是总需求/总发送能力
分类¶
P2P 分为
- 非结构化 P2P
- 集中化目录:Napster
- 坏处:单点故障、性能瓶颈、侵犯版权
- 非集中化目录:Gnutella
- 混合体:KaZaA
- 分为组长和组员
- 在组内,相当于 Napster
- 组长知道组员的一切,并把一切告诉组员
- 在组外,相当于 Gnutella
- 如果查询的东西组内没有,那么,组长就代表整组,向其他组长进行询问,并保存副本
- 查询的话,也是组长进行中转。具体地,
- 每一个文件有散列标识码和一个描述符
- 组员发送关键字给组长,组长转发请求到其他主机
- 其他主机返回匹配响应。响应的每一个 entry 包括:
- 文件元数据
- 散列标识码
- IP 地址
- 客户端从中选择符合自己的散列标识码的 entry,并向对应 IP 地址进行请求
- DHT(分布式哈希表,或者意译为“结构化”)P2P:节点之间构成某种(应用层上的、逻辑上的)树状、网状等关系
应用:BitTorrent¶
名词介绍¶
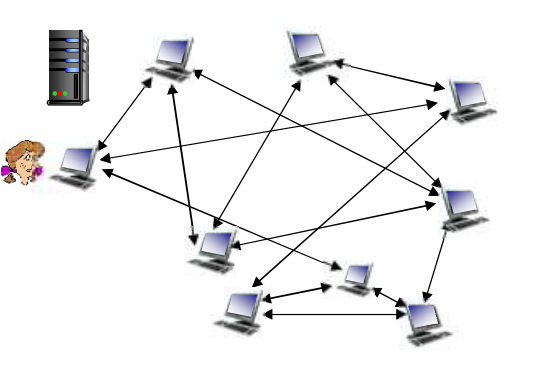
- 文件被分为一个个块256KB
- 网络中的这些peers发送接收文件块,相互服务
左上角的黑色服务器,就是 tracker,负责追踪 torrent 的参与节点。
torrent,就是一些节点的列表,以及服务/被服务的关系。我们需要加入“洪流”,才能互通有无、互传文件。
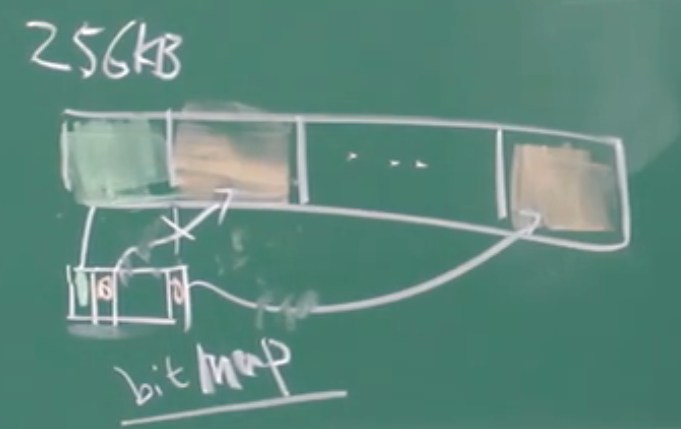
互通的有无(通常是一个文件),以 256 KB 为一个单位,称为“块”。我们使用一个 "bitmap" 来跟踪我们是否拥有某一块,如图(1 代表”我拥有该内容“,0 代表没有):
节点行为¶
对于整个洪流,每过一段时间,这些节点就会”泛洪“,也就是互相交换 bitmap。从而,节点之间就知道了其他节点的“有无”情况。
对于一个新加入洪流的节点,
- 先请求随机 4 块内容
- 之后,优先请求稀缺块
- 这样,首先集体的利益有保障(单点故障概率减少)
- 其次,拥有稀缺节点的块,被请求的概率高,因此,就有更多的机会向其它块服务
- 根据“一报还一报”的策略,其它块也就更倾向于(在它有需求时)向他服务
一报还一报:
- 以三个小周期为一个大周期,对于前两个小周期,对于整个请求列表,我都会服务前 \(n\) 个对我好的节点(\(n\) 为我同时服务节点的数量)
- 最后一个小周期,我会随机在请求列表中选一些节点进行服务(希望找到“黑马”)
.torrent 文件¶
torrent文件内容格式如下,所有的字符串均使用UTF-8编码:
- announce: tracker服务器的地址
- announce-list:
- created by: 创建者
- creation date: 创建时间
- encoding: UTF-8
- info: 待下载的文件信息
- files:
- length: 文件长度
- path: 文件下载路径
- name: 下载文件时所使用的文件名
- piece length: 每个数据块的大小,通常是256KB
- pieces: 哈希列表,包含了每个数据表的哈希值(SHA-1),将每个数据块的哈希值拼接在一起。由于SHA-1计算出的哈希值是160位的,因此pieces的值也是160的整数倍。如果torrent文件中包含了多个待下载文件,则这些文件的数据块的哈希值会按顺序排列在pieces中。
我们向检索网站(比如海盗湾)查询的时候,检索网站会给我一个 .torrent 文件。然后,我通过 tracker 列表,向 tracker 进行请求,然后 tracker 会给我服务这些文件的一些 peers。
网络特征¶
-
Peer加入torrent:
-
一开始没有块,但是将会通过其他节点处累积文件块
-
向跟踪服务器注册,获得 peer节点列表,和部分peer 节点构成邻居关系 (“连接 ”)
-
当peer下载时,该peer可以同时向其他节点提供上载服务
- 兼备 C/S 的功能
- Peer可能会变换用于交换块的peer节点
- 服务对象易变
- 扰动churn: peer节点可能会上线或者下线
- 服务不稳定
- 一旦一个peer拥有整个文件(i.e. 整个 bitmap 为 1,另外该 peer 被称为“种子”),它会(自私的)离开或者保留(利他主义)在torrent中
应用:Gnutella¶
- 全分布式(包括查询)
- 使用泛洪(flooding)的方式查询
- 使用 TTL 或者标记重复的方式,避免泛洪查询信息不断回荡在全网上
缺点:
- 网络建立、维护困难
- 软件在下载的时候,就会附带一个列表,帮助建立起初始的 overlay
总体而言,这个网络很不成功。
Lec 2.7: CDN¶
背景和挑战¶
视频流化服务(也就是边传边播的服务,不同于必须先下载再播放的传统)是互联网的一个 killer application,消耗带宽极大(Netflix 和 YouTube 占据了 ISP 的 37%,16% 的下行带宽)。因此,除了流量极大以外,还有两个挑战
- 规模性:单个服务器无法承受如此大的访问压力
- 注意和流量大不一样,比如电话系统的用户规模虽然大,但是流量很小
- 异构性:不同用户拥有不同的能力(例如:有线接入和移 动用户;带宽丰富和受限用户)
多媒体:视频¶
视频特点:
- 高码率:>10x 于音频
- 可压缩性:由于视频信息的冗余度很大,可以压缩的空间很大
- 空间(一张图片内)和时间(相邻的图片之间)的冗余度都很大
- 占据网络流量的 90%
流视频传输¶
服务器在获得视频之后,会将其转换成多种码率,并逐个进行切片,将其变成若干个小 HTTP 块,便于流式传输。
客户端向服务器请求视频时,服务器会向你传输一个告知文件 (Manifest File),告诉你各种码率视频的信息和请求格式,如下:
<AdaptationSet mimeType="video/mp4" segmentAlignment="true">
<Representation id="1" bandwidth="1000000" width="1280" height="720" codecs="avc1.4d401f">
<BaseURL>http://example.com/video_1.mp4</BaseURL>
</Representation>
<Representation id="2" bandwidth="500000" width="854" height="480" codecs="avc1.4d401e">
<BaseURL>http://example.com/video_2.mp4</BaseURL>
</Representation>
</AdaptationSet>
其中,
id:表示该版本的唯一标识符。bandwidth:表示该版本的码率,以比特率(bits per second)为单位。width和height:表示该版本的视频宽度和高度。codecs:表示该版本的视频编解码器。
之后,客户端向服务器请求视频块,服务器会使用 DASH(Dynamic Adaptive Streaming over HTTP)等协议向客户端传输。
同时,客户端会根据
- 自己的实时带宽大小
- 自己的缓冲区大小
来智能决定
- 什么时候请求(避免缓存溢出或者不足)
- 请求什么码率(带宽大时,尽量请求高质量视频块)
- 去哪里请求(就近请求 or 向带宽大的服务器进行请求)
从而,客户端异构性的问题得以解决(动态使用码率)。
带宽瓶颈和重复流量的解决方案:CDN¶
由于
- 服务器和源主机之间可能有很多跳,这些跳之间的薄弱环节就是带宽瓶颈
- 由于一个地区的用户的请求同质化,因此会有大量的重复流量
因此,就像我们之前说的 Web Cache 一样,不仅 ISP 会使用,ICP 也会使用类似的技术——这就是 CDN (Content Delivery Network)。
- 注意:ISP 的缓存比 CDN 小得多,而且主要用于缓存网页内容。
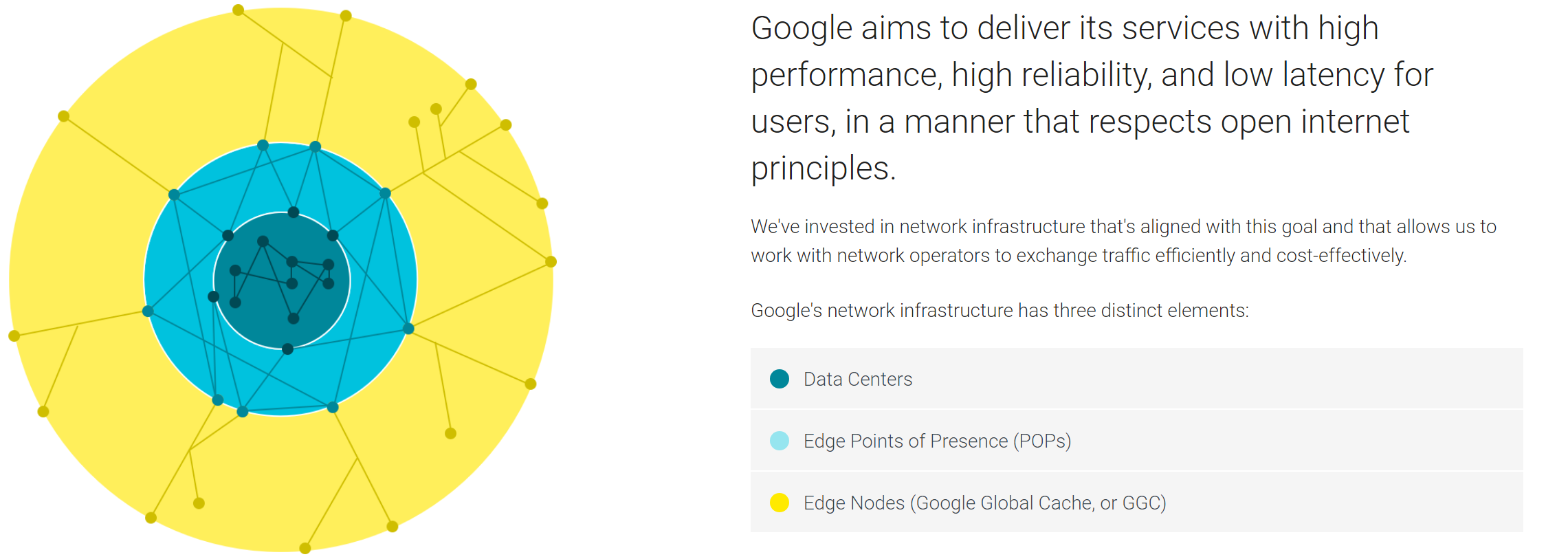
CDN 部署策略¶
CDN 将节点部署在全球,并缓存 ICP 的内容,以便于快速、大量分发。一般采用的会有两种策略:
- Enter Deep: 在 local ISP 中部署 CDN 服务器
- 优点:更接近用户
- 缺点:节点数量大、管理困难
- Bring Home: 部署在少数位置,比如 Peer 1 ISP 的 POP 附近
当然,有些是 mixed,比如 Google:
CDN 工作原理¶
用户先从源服务器上获取 manifest file,然后根据文件里的(多个)CDN 的 <BaseURL>,选择一个最适合自己的,进行访问。
从而,CDN 对服务器而言,提供的是“(帮你把)内容分发服务”;对客户而言,提供的是“内容加速服务”。
CDN 特点: Over the Top (OTT) & On the Edge¶
CDN 工作在网络边缘,同时也工作在应用层(也就是 Over The Top)。
CDN 的挑战¶
- 从哪一个缓存节点获取内容?
- 用户在网络堵塞情况时的行为?
- 在哪些 CDN 里储存哪些内容?
案例学习:Netflix¶
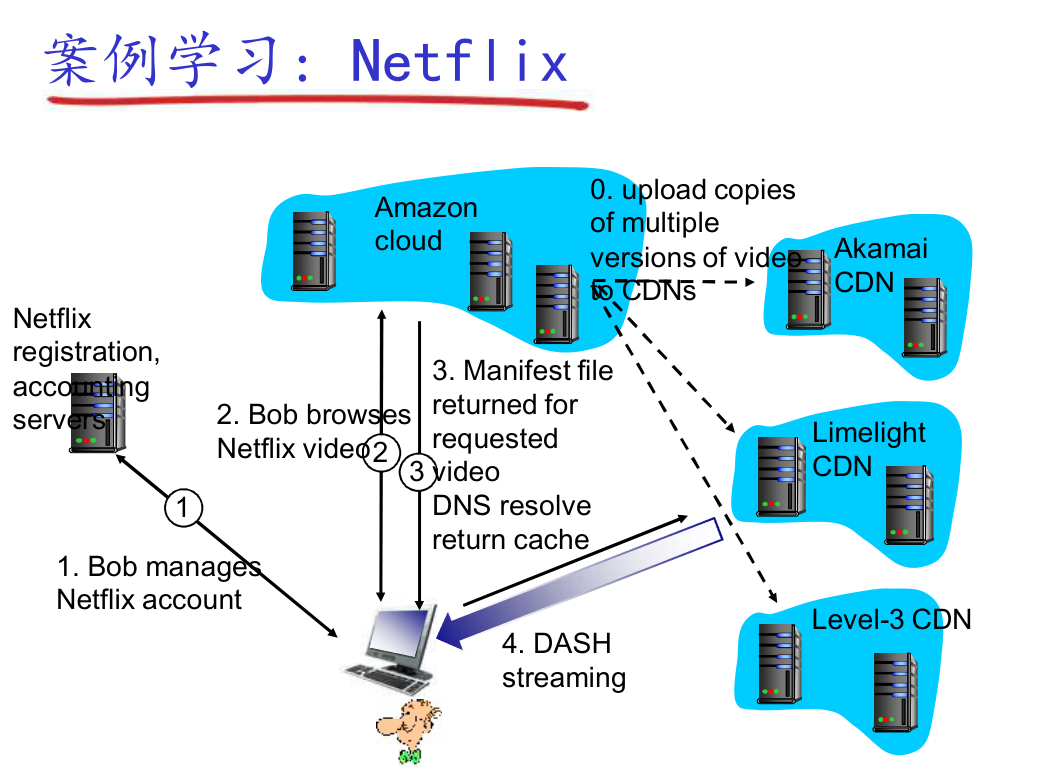
注意:很多情况下,<BaseURL>的域名会 CNAME 到 CDN 服务器。从而,你首先请求 base URL,然后再请求其 CNAME,也就是 CDN 节点域名。
为什么要有 CNAME 呢?因为 CDN 有自己一套域名管理规范,ICP 也有一套规范。两个规范通过 CNAME 这个“接口”接在一起。
由于这一切都是在 DNS 中完成的,因此 DNS 之外的应用层完全无感。