8. CNN Architectures
Hardware Usage Analysis¶
Take AlexNet as example:
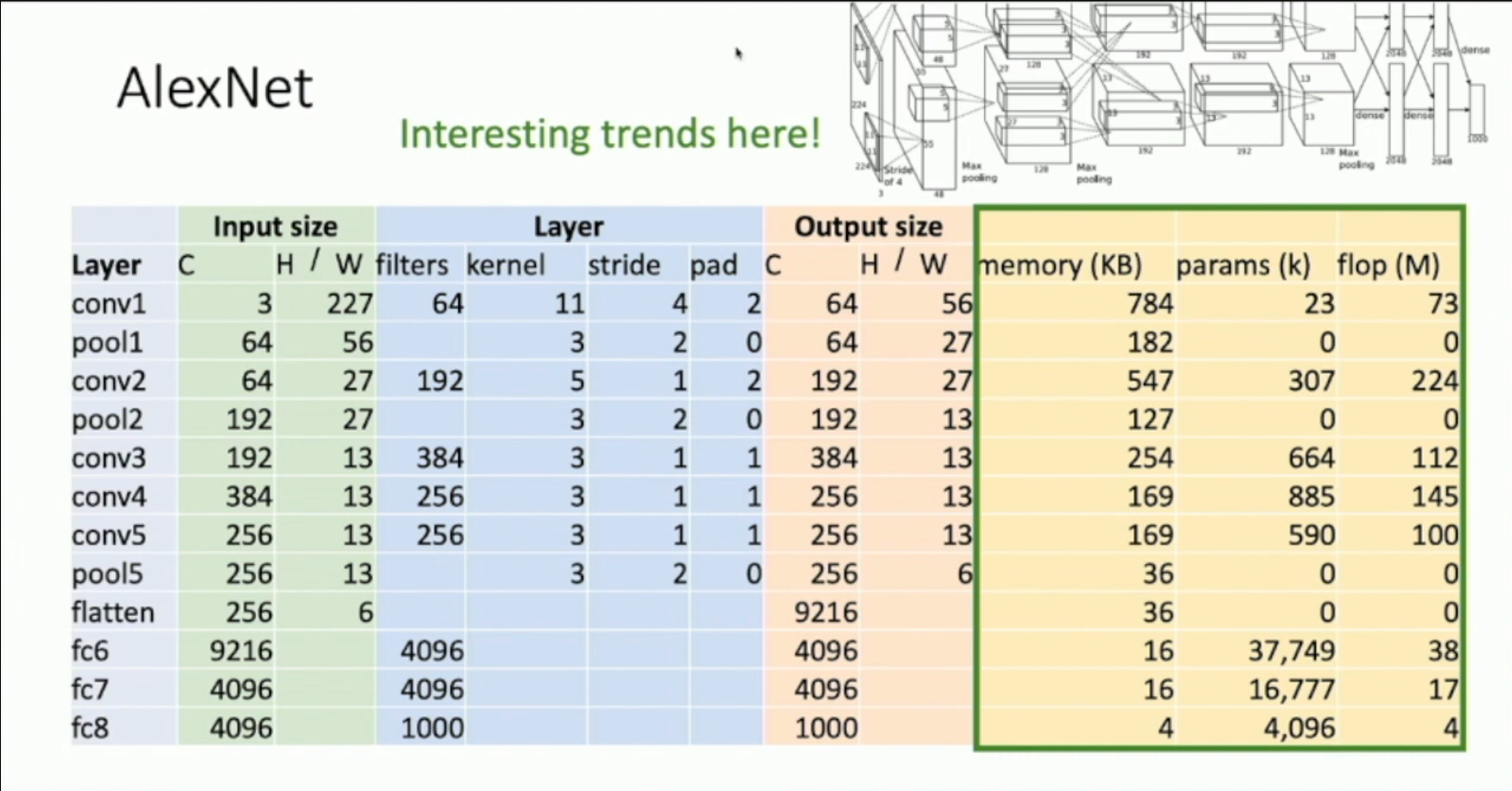
Terminology:
-
Memory: the memory that the output of this layer uses
- Conv: Memory = C_out * H_out * W_out * sizeof(data type)
- e.g. 64 * 56 * 56 * 4 = 802816 bytes ≈ 784 KiB
- Conv: Memory = C_out * H_out * W_out * sizeof(data type)
-
Params: the number of parameters of this layer
- Conv: Params = C_out * C_in * kernel_size
- e.g. 64 * 3 * 121 = 23232 ≈ 23K
- Conv: Params = C_out * C_in * kernel_size
-
Flop (Floating-point operations): the number of multiplicative flops needed for this layer
- Conv: Flop = C_out * H_out * W_out * C_in * kernel_size = Params * H_out * W_out
- e.g. 64 * 56 * 56 * 3 * 121 = 72855552 ≈ 73M
- Conv: Flop = C_out * H_out * W_out * C_in * kernel_size = Params * H_out * W_out
我们可以将这三个数据放到直方图中。以 AlexNet 为例:
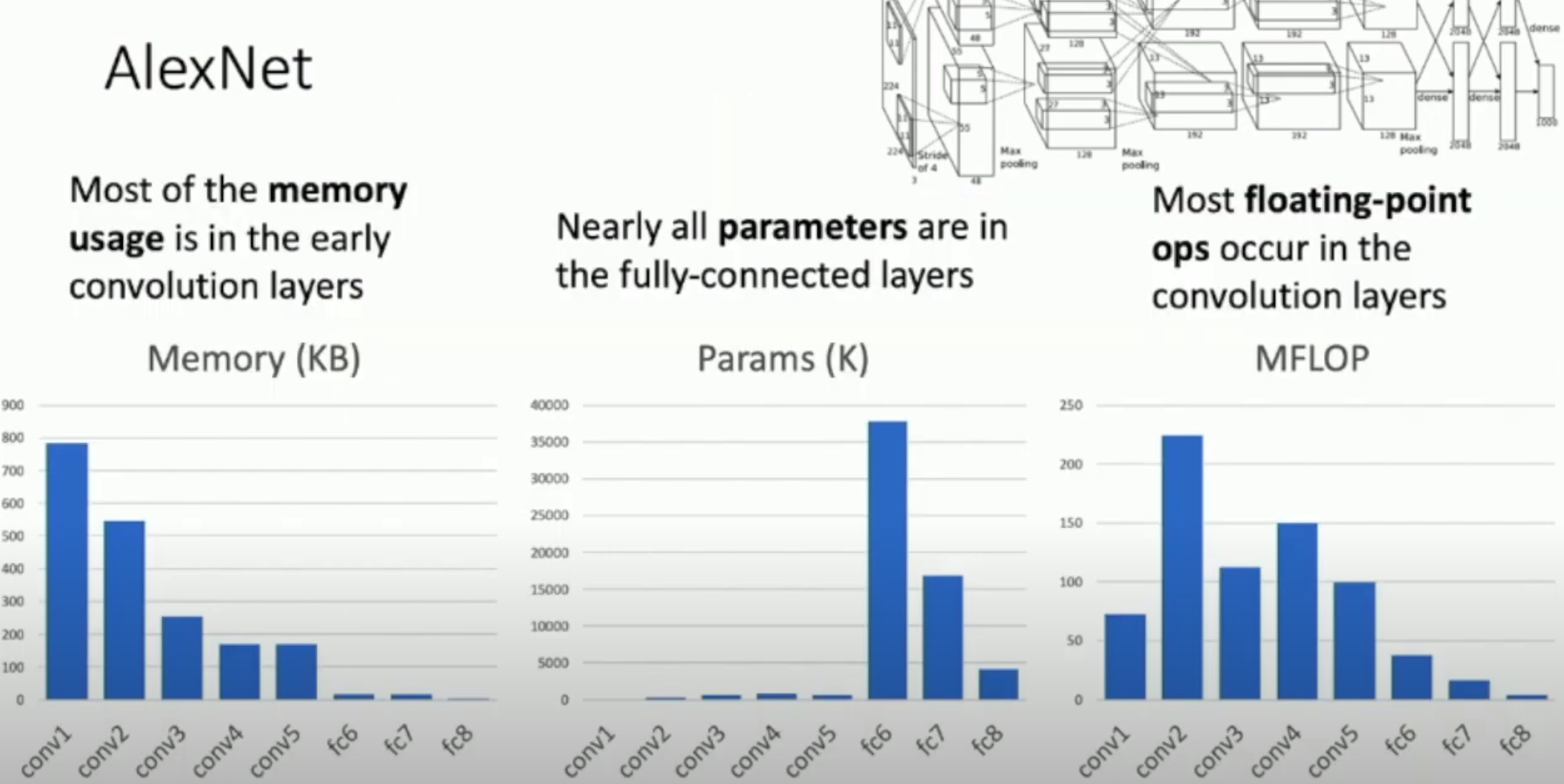
可以发现,
- 内存主要被最开始的卷积层使用
- 参数主要被最开始的全连接层使用
- (浮点乘法)计算主要被卷积层使用
- 特别是卷积核比较大+通道数比较多+图片尺寸比较大的层
注意:由于池化层不会占用参数,几乎不怎么消耗算力,所以我们在直方图中忽略它(
Famous CNN Architectures¶
2014: VGG¶
相比之前的 ad-hoc architecture,VGG 采用了一种设计理念,来指导网络的设计:
- 采用 3 × 3 with stride 1 and padding 1 convolution
- n 个 3 × 3 相比 1 个 (2n+1) × (2n+1) 而言,参数数量和浮点计算量都减少了很多,但是视野不变
- n 个 3 × 3 可以有 ReLU 层连接。相比 (2n+1) × (2n+1),非线性性更好
- 将 5 层 conv 变成 5 个组件,每一个组件由若干个 conv 和一个 2 × 2 with stride 2 pooling
- 前面的几个组件之间,后一个比前一个的 # of channels 多一倍,同时由于 pooling,H/W 也是前一个的 1/2

2014: GoogLeNet¶
为了减少运算、内存、参数,从而更好地应用于工业界,GoogLeNet 采用了与众不同的模块。
- 迅速将 224 × 224 的图片 pooling 到 28 × 28
- 为了减小浮点运算数量和内存消耗
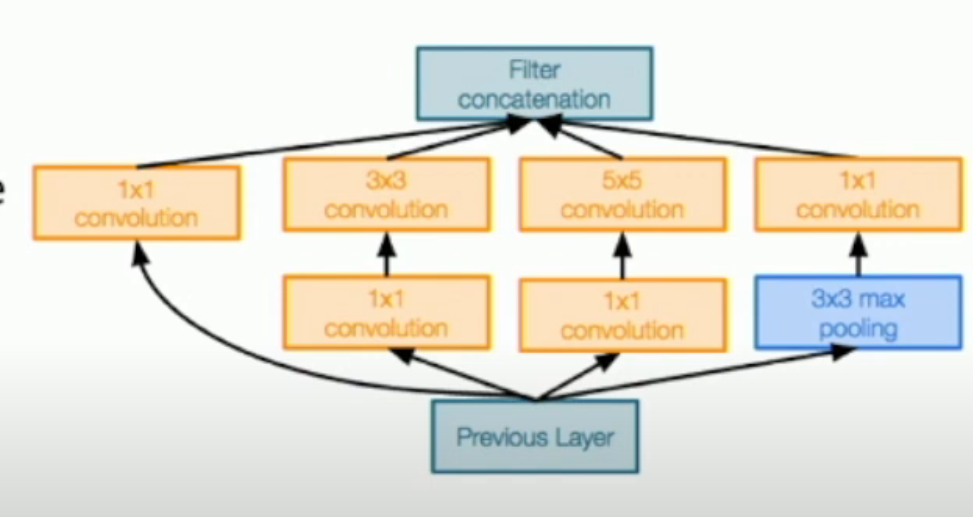
- 采用 Inception Module 作为网络的基本单元
- 避免调整网络结构这个“超参数”
- btw,1 × 1 convolution 可以用于快速减小数据的通道数
- 最后的全连接层只有一层,为 1024 → 1000。在这一层之前,使用 global average pooling,将 7 × 7 的图片直接变成 1 × 1(当然通道数不变,还是 1024)
- 为了减小参数数量
Interception Module:
Global Average Pooling:

Sidenote: Before Batch Normalization¶
在 Batch Normalization 出现之前,对于深层网络(层数大于 10),人们都需要通过一些 hack(比如 GoogLeNet 的 auxiliary module)来避免梯度消失/爆炸。
在 Batch Normalization 出现之后,这个问题得到了很好的缓解。
2015: ResNet¶
Does scaling always work?
根据以往的经验,人们发现,似乎层数越多,in/out-of-sample error 就都越小。
但是,当层数从 20 层上升至 56 层的时候,层数的增加,反而使得 out-of-sample error 更大。这难道是因为传说中的 over-fitting?
可是,不仅 out-of-sample error 增加了,in-of-sample error 竟然也增加了(如下图所示)。
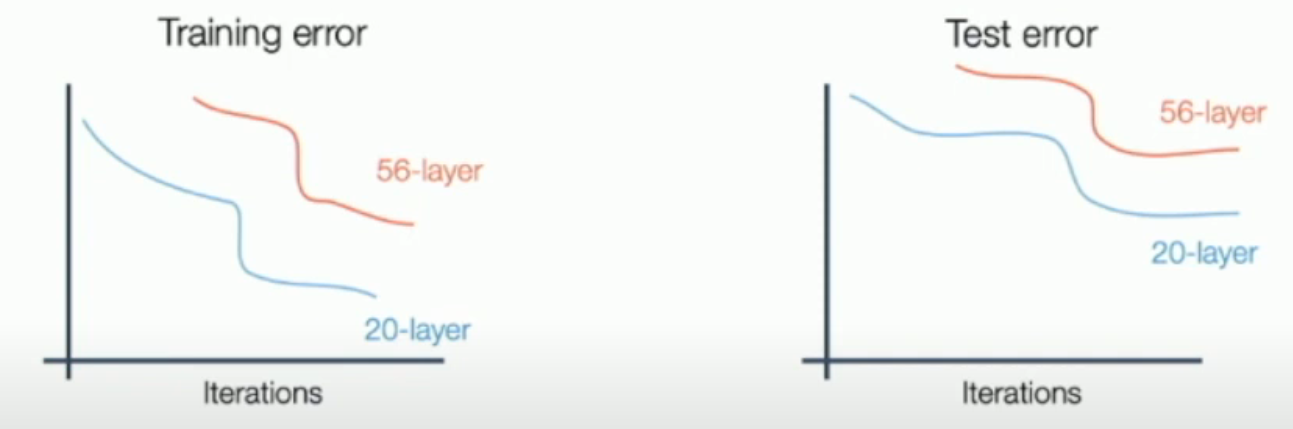
这就说明,56 层并不是过拟合,而似乎是欠拟合。虽然 56 层的 hypothesis set 更大,但是其实 "practical hypothesis set (within some epoch limit)" 反而更小。
这是什么问题呢?是一个优化方法上的问题。由什么导致呢?因为梯度消失/爆炸。如何解决呢?ResNet 给出了一个令人满意的答案。
ResNet 解决的问题:
- 梯度消失
- 计算/空间复杂性:还是采用了 GoogLeNet 的 aggressive down-sampling at the beginning and global average pooling at the end.
Bottleneck Block¶

如图,我们与其使用左侧的 residual block,不如使用右侧的。因为右侧的 block 不仅增加了 non-linearity,还减少了 computational cost。
Improved ResNet: ResNeXt¶
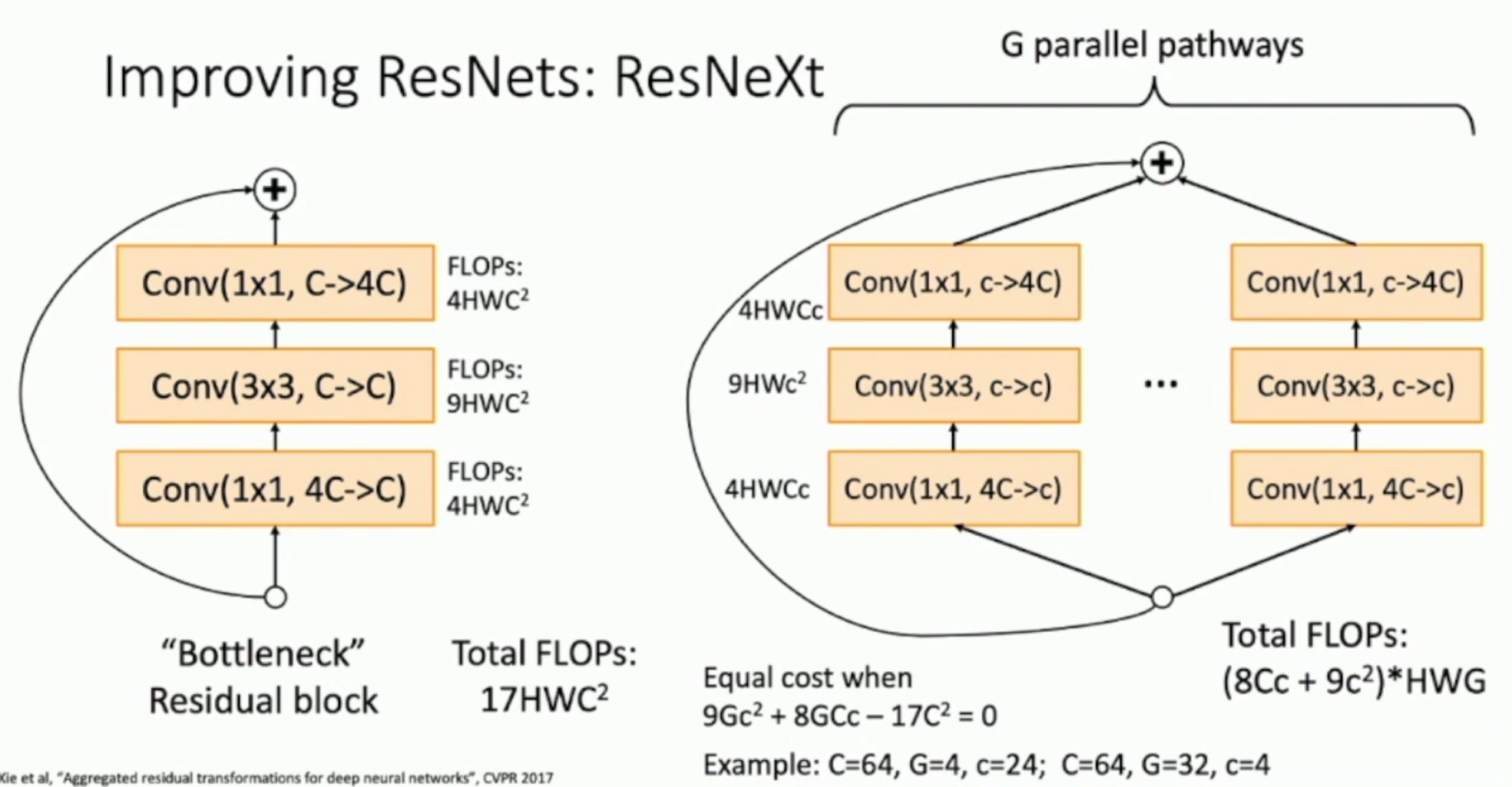
如图:在右侧,我们通过 1 × 1 conv 将通道数减小到更小,但是增加并行的网络。
我们可以得到算式 \(9Gc^2+8GCc-17C^2=0\) 来解出在同样算力支持下,如何均衡通道数和并行数。
Practice in PyTorch¶
在 PyTorch 中,对于并行的网络,我们采用 group convolution 来实现:
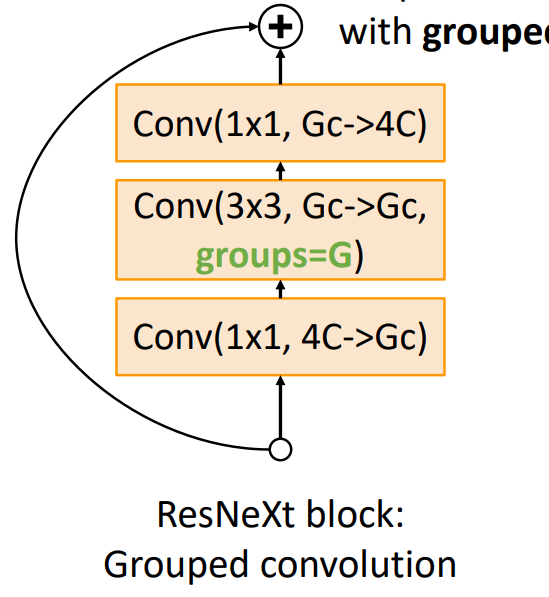
其中,group convolution 就是将通道进行分组,进行卷积计算,然后再 concatenate:
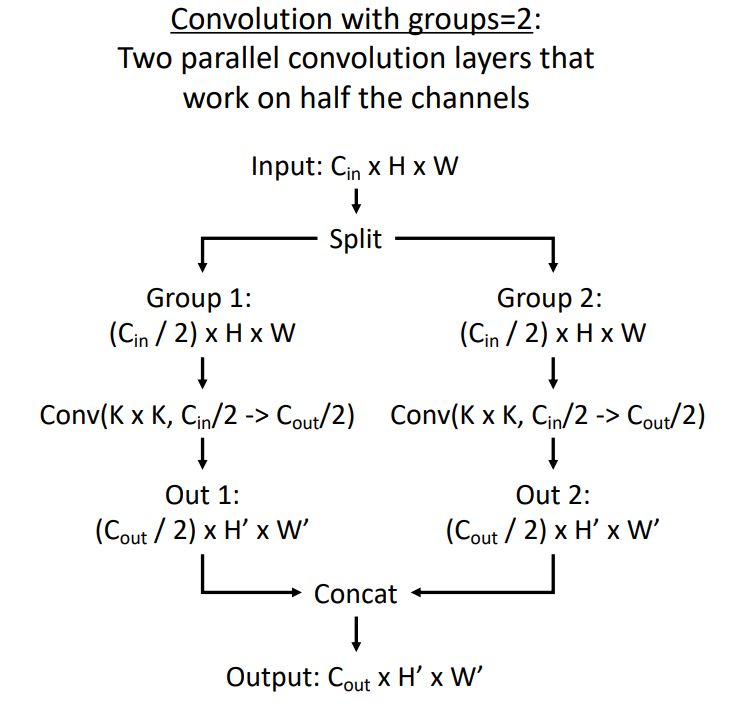
不难发现,使用 group convolution 和使用并行网络是完全等价的。
另外,实际测试中,使用相同的算力,增加 \(G\) 的数量,确实会使得网络性能更好。
MobileNets: Tiny Networks (For Mobile Devices)¶
如果要部署 local deep learning network,那么就必须考虑到 local devices 算力的差距。对于手机等弱算力设备,我们必须用 accuracy 来换取 time/space efficiency.
如图,右侧的结构被广泛用于 tiny network design 之中。
- 左侧的结构,我们同时在 channel 上进行线性变换和 2D depthless image 上进行卷积
- 右侧的结构,我们先在 2D depthless image (i.e. depthwise convolution) 上进行线性变换,然后再在 channel (i.e. pointwise convolution) 上进行卷积。从而在完成了两项任务的同时,减小了运算量。

Also related:
- ShuffleNet: Zhang et al, CVPR 2018
- MobileNetV2: Sandler et al, CVPR 2018
- ShuffleNetV2: Ma et al, ECCV 2018
Densely Connected Neural Networks¶
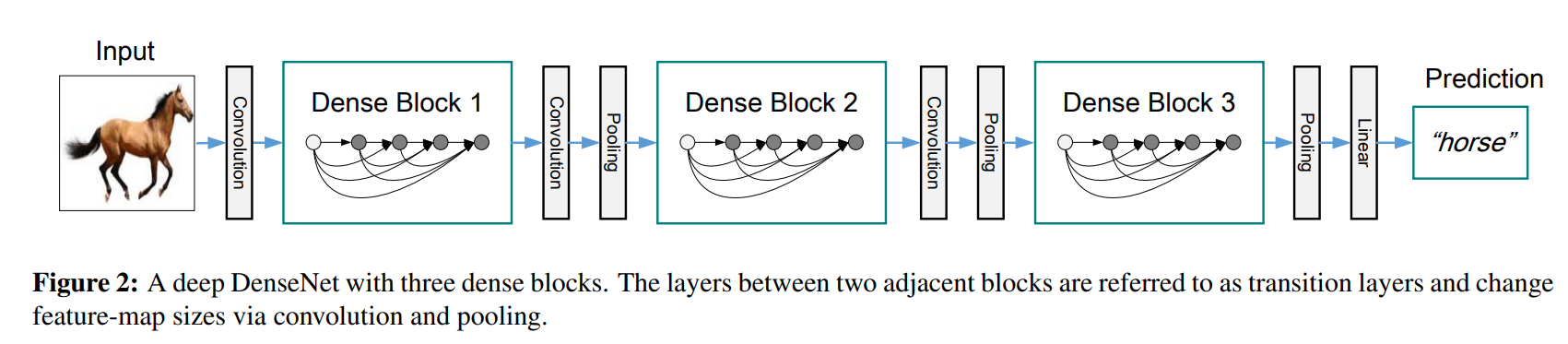
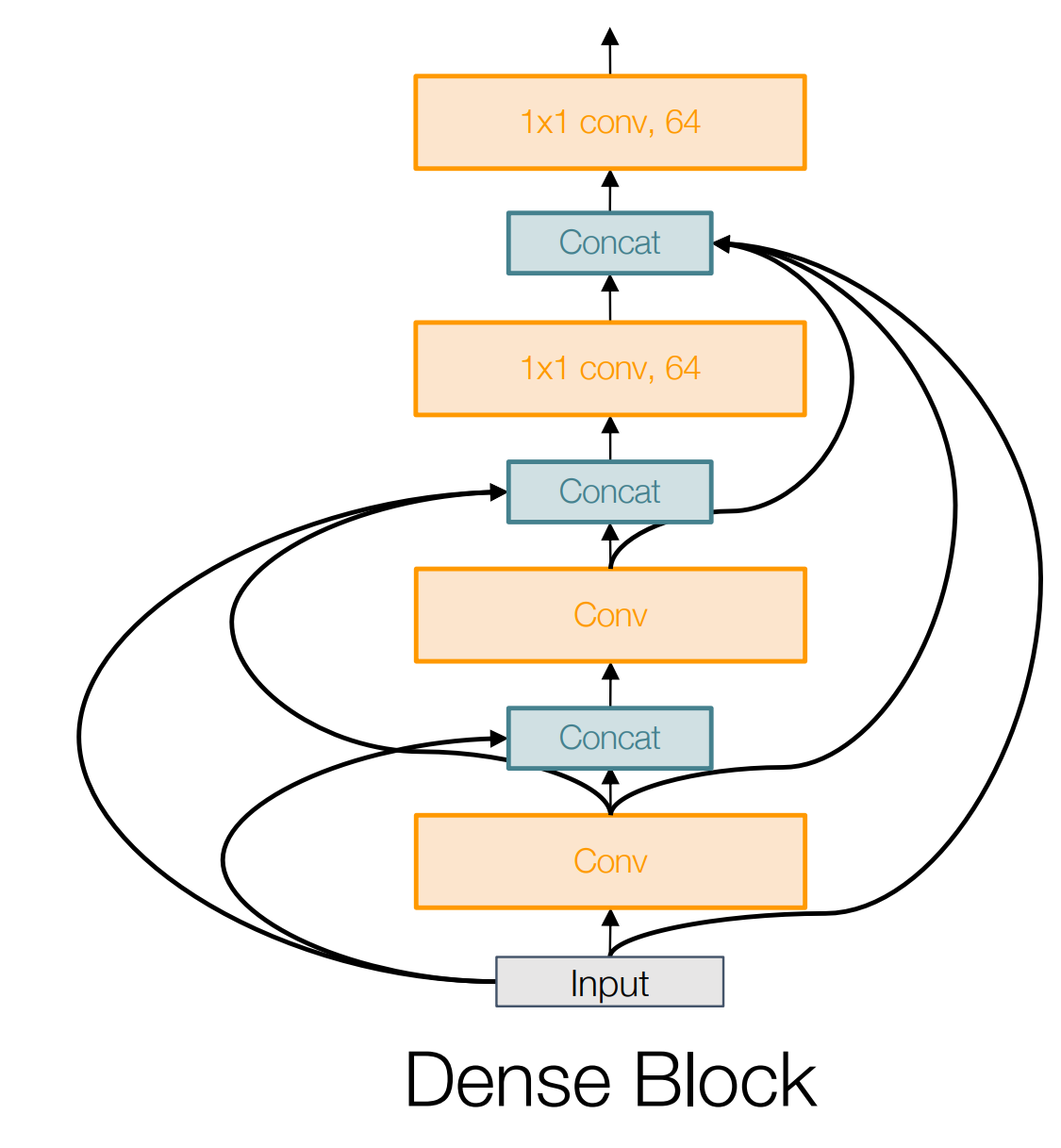
如上图,dense block 可以
- Alleviates vanishing gradient
- strengthens feature propagation
- encourages feature reuse
其中,后两点的意思是:卷积的时候,可能会造成特征损失,从而后面的层就用不了前面的前面的特征。我们使用更加密集的连接,保证了后面的层能够有效获取前面各层的特征。
Neural Architecture Search¶
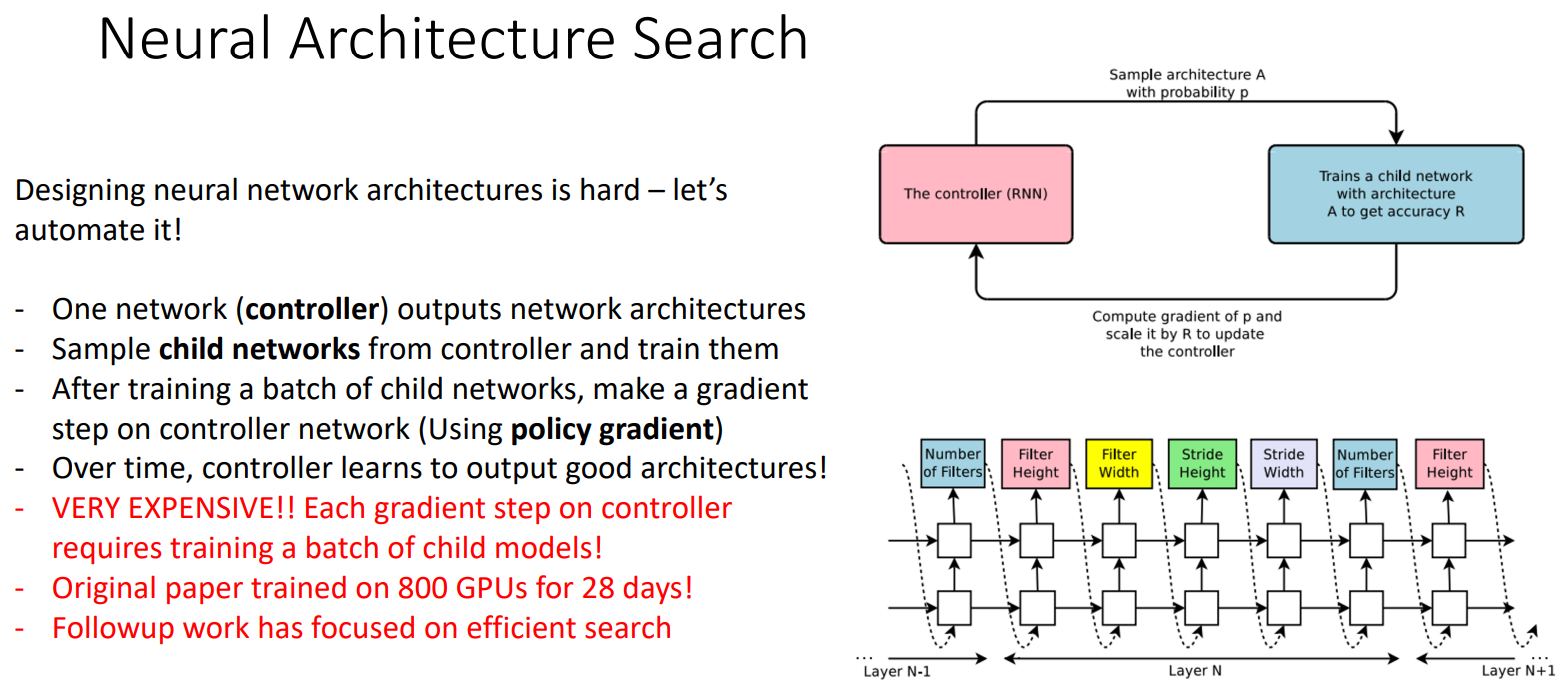
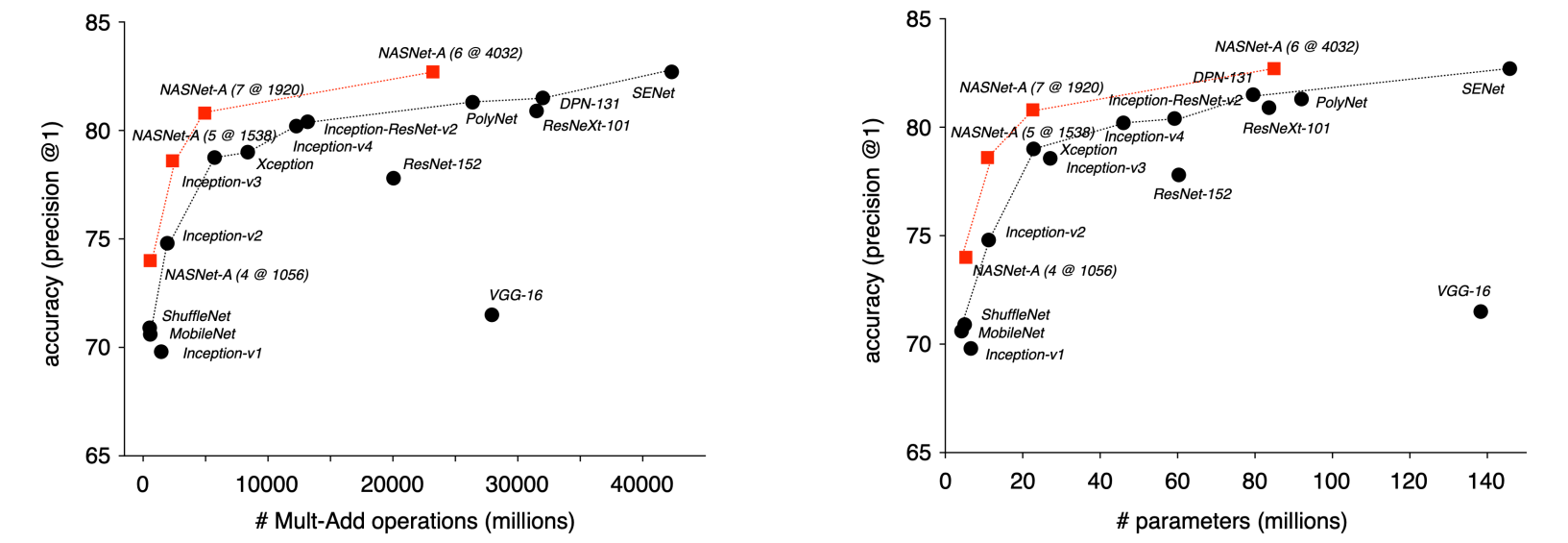
我们训练能够生成神经网络架构的 "meta" 神经网络,然后以生成的神经网络训练后的 out-of-sample error 为误差,进行梯度下降迭代。最后得到了更好的神经网络架构(如下图的 NASNet)。
Conclusion¶
- 早期的工作(AlexNet -> ZFNet -> VGG)似乎表明了:越大的网络效果越好
- GoogLeNet 是第一个 focus on efficiency 的架构
- 后来,非常大的网络很容易出现梯度消失,从而反而效果变差。而 ResNet 是第一个训练出超深层网络的架构
- 在 ResNet 之后,efficient network 变成了重中之重:如何在算力/储存/内存不变的情况下,训练出更高效的网络?
- 同时,tiny network that sacrifice accuracy for computational tractability 出现了
- NAS 希望能够称为”元“神经网络——automates architecture design
也就是说,研究者关注的问题是(以时间顺序排序):
- 什么样的网络更好?深层网络。
- 怎么训练深层网络?ResNet。
- 深层网络训练太耗资源,怎么办?优化网络结构,focus on efficiency。
- 有没有一种自动优化网络结构的方法?使用 NAS。
最后,我们应该用什么样的网络?Here are three rules of thumb:
- Don’t be a hero. For most problems you should use an off-the-shelf architecture; don’t try to design your own!
- If you just care about accuracy, ResNet-50 or ResNet-101 are great choices
- If you want an efficient network (real-time, run on mobile, etc) try MobileNets and ShuffleNets